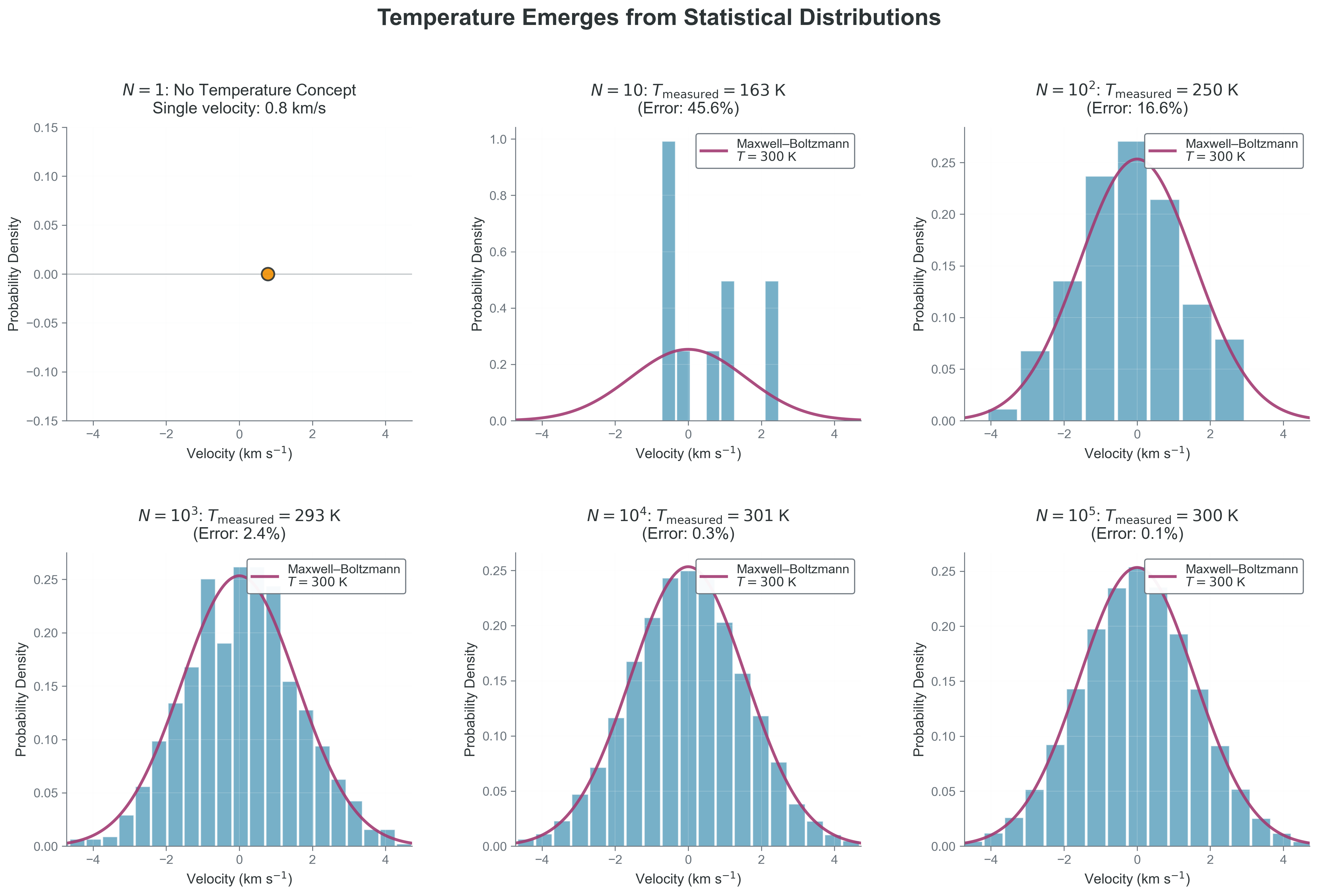
def infer_temperature_proxy(n_samples, sigma_true=1.0):
v = rng.normal(0.0, sigma_true, n_samples)
variance = np.var(v, ddof=1)
return variance
for n in [20, 200, 2000, 20000]:
var_hat = infer_temperature_proxy(n)
print(f"N={n:5d} variance~{var_hat:0.4f}")
print("Interpretation: larger N gives a more stable estimate of ensemble properties.")N= 20 variance~1.1810
N= 200 variance~0.8353
N= 2000 variance~0.9754
N=20000 variance~1.0213
Interpretation: larger N gives a more stable estimate of ensemble properties.