The Beautiful Failure
COMP 536 | Numerical Methods
2026-04-28
Warmup Result: Euler Works… Okay
t_exact = np.linspace(0, t_end, 200)
fig, ax = plt.subplots(figsize=(9, 3))
ax.plot(t_exact, np.exp(-t_exact), 'k-', lw=2, label='Exact: $e^{-t}$')
ax.plot(t_vals, y_vals, 'ro-', label=f'Euler ($h = {h}$)', markersize=8)
ax.set(xlabel='Time', ylabel='$y(t)$',
title='Exponential Decay: Euler Works... Okay')
ax.legend(fontsize=12)
plt.tight_layout()
plt.show()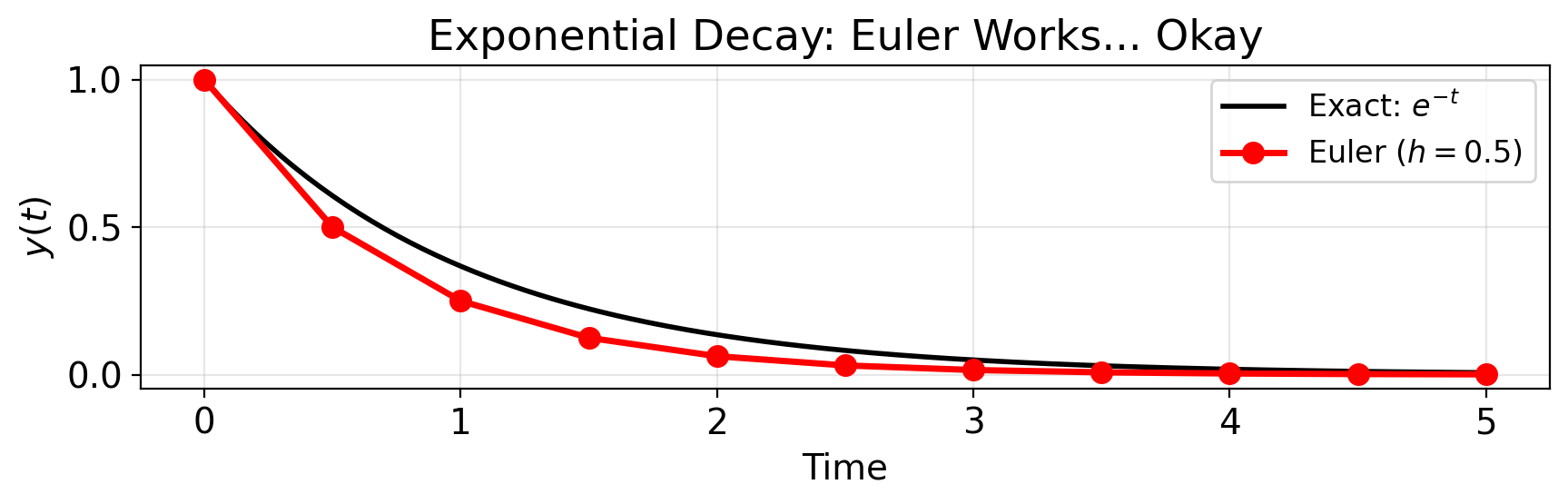
The Beautiful Failure: Trajectory
h = 0.1; t_end = 20 * np.pi # 10 periods
t_euler, y_euler = euler_integrate(f_sho, y0_sho, [0, t_end], h)
fig, ax = plt.subplots(figsize=(10, 3))
ax.plot(np.linspace(0, t_end, 2000), np.cos(np.linspace(0, t_end, 2000)),
'k-', alpha=0.5, lw=1.5, label='Exact')
ax.plot(t_euler, y_euler[:, 0], 'r-', lw=1, label=f'Euler ($h={h}$)')
ax.set(xlabel='Time', ylabel='$x(t)$')
ax.legend()
plt.tight_layout()
plt.show()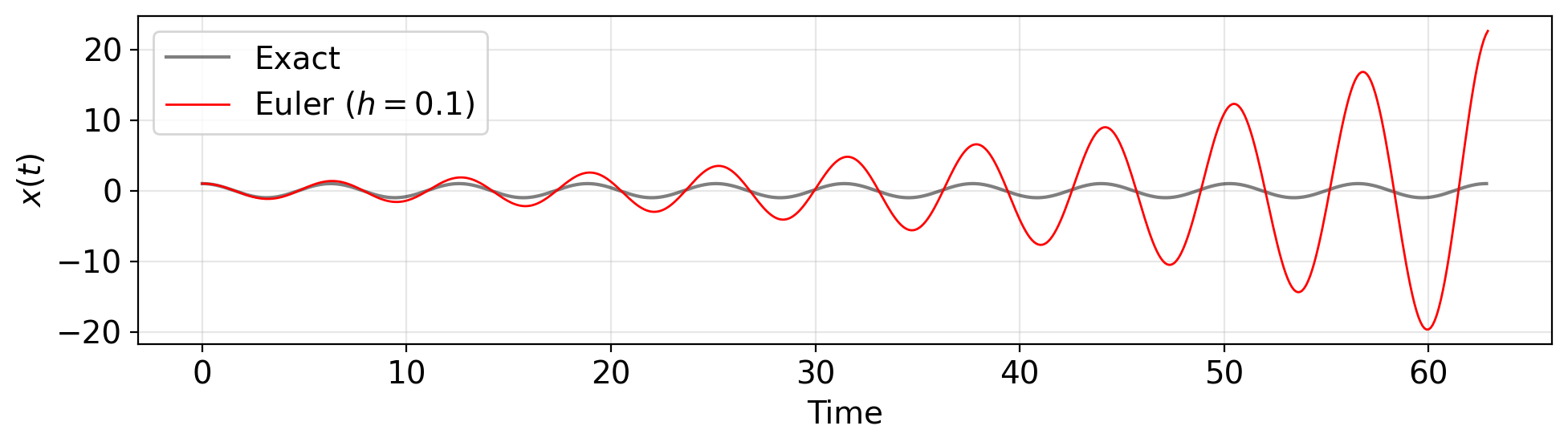
Phase Space Reveals the Crime
fig, ax = plt.subplots(figsize=(5, 4))
theta = np.linspace(0, 2 * np.pi, 200)
ax.plot(np.cos(theta), -np.sin(theta), 'k--', lw=2, label='Exact (circle)')
ax.plot(y_euler[:, 0], y_euler[:, 1], 'r-', lw=0.5, alpha=0.7,
label='Euler (spiral)')
ax.set(xlabel='Position $x$', ylabel='Velocity $v$',
title='Phase Space: Euler Spirals Outward')
ax.set_aspect('equal')
ax.legend()
plt.tight_layout()
plt.show()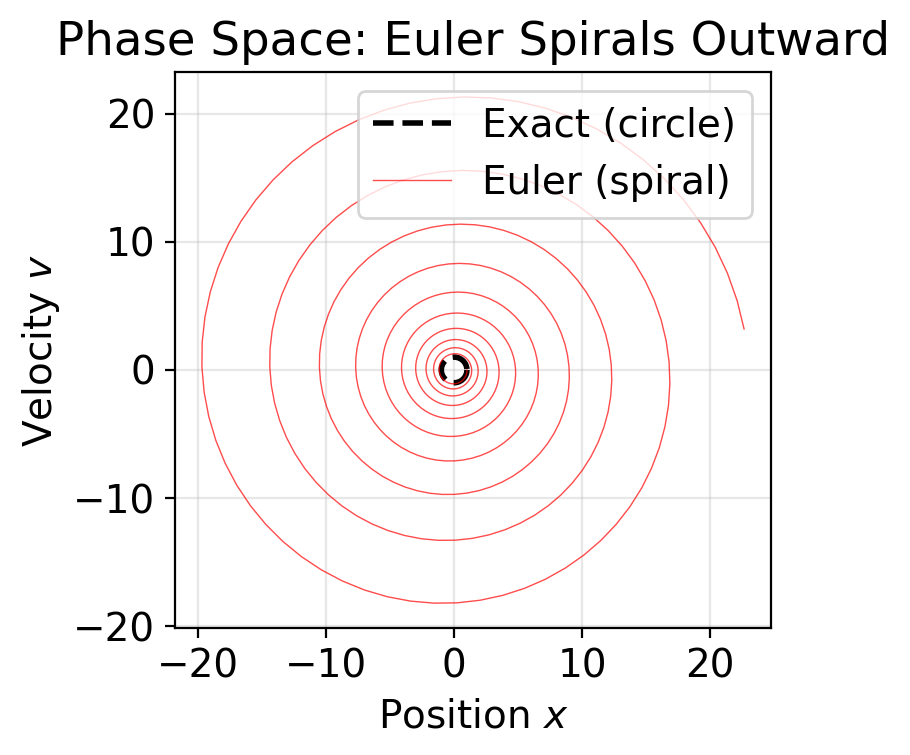
Energy Tells the Story
# Total energy: E = (1/2)(v^2 + omega^2 * x^2). For omega=1: E = (x^2 + v^2)/2
E_euler = 0.5 * (y_euler[:, 0]**2 + y_euler[:, 1]**2)
fig, ax = plt.subplots(figsize=(9, 3))
ax.plot(t_euler, E_euler, 'r-', lw=2, label='Euler')
ax.axhline(0.5, color='k', ls='--', lw=1.5, label='Exact ($E = 0.5$)')
ax.set(xlabel='Time', ylabel='Total Energy $E$',
title='Energy Conservation: Euler FAILS')
ax.legend()
ax.set_ylim(0, min(E_euler[-1] * 1.1, E_euler[-1] + 50))
plt.tight_layout()
plt.show()
print(f"Energy at start: {E_euler[0]:.4f}")
print(f"Energy at end: {E_euler[-1]:.1f}")
print(f"Energy grew by: {(E_euler[-1] / E_euler[0] - 1) * 100:.0f}%")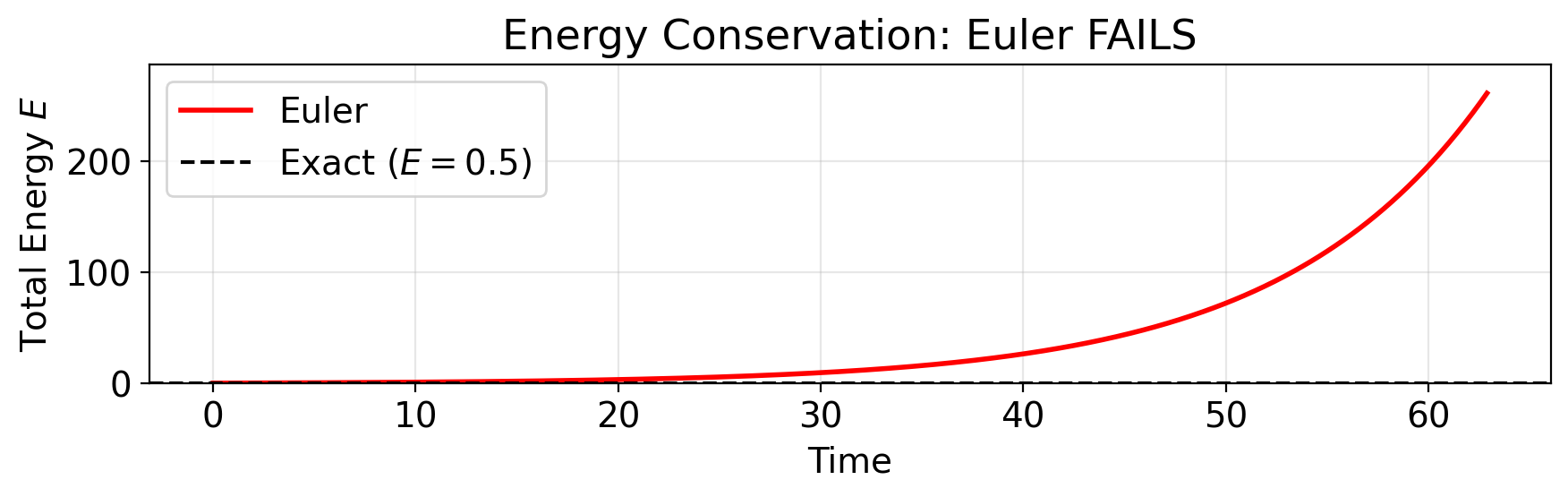
Energy at start: 0.5000
Energy at end: 261.3
Energy grew by: 52157%RK2 vs Euler: Trajectory
t_rk2, y_rk2 = rk2_integrate(f_sho, y0_sho, [0, t_end], h)
fig, ax = plt.subplots(figsize=(10, 3))
ax.plot(t_exact, np.cos(t_exact), 'k-', alpha=0.4, lw=1.5, label='Exact')
ax.plot(t_euler, y_euler[:, 0], 'r-', lw=0.8, alpha=0.5, label='Euler')
ax.plot(t_rk2, y_rk2[:, 0], 'b-', lw=1.5, label='RK2')
ax.set(xlabel='Time', ylabel='$x(t)$',
title='RK2 vs Euler: Night and Day')
ax.legend()
plt.tight_layout()
plt.show()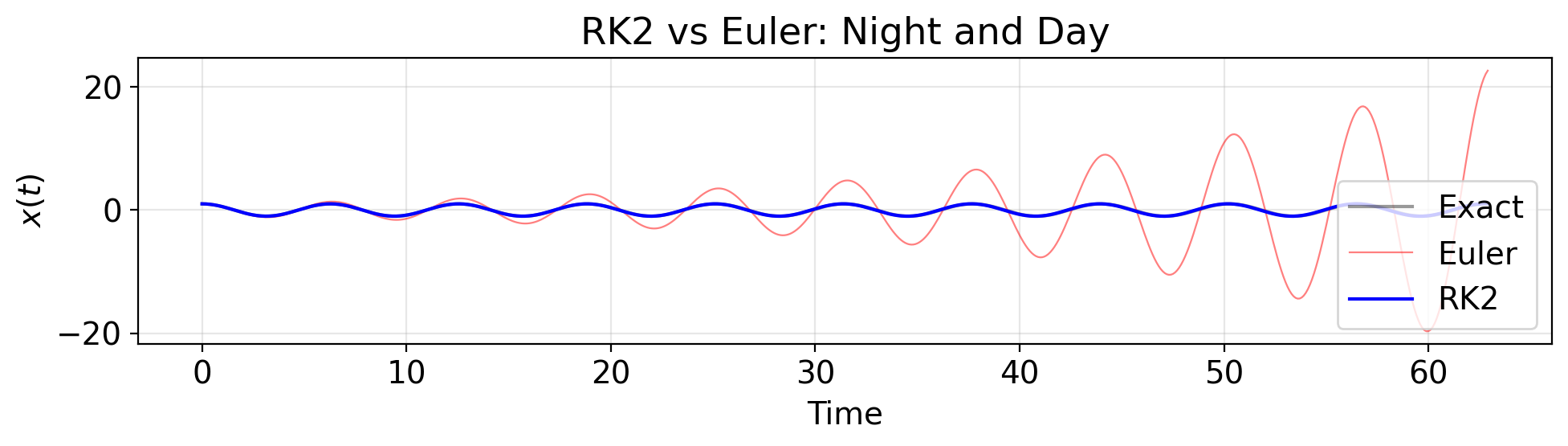
RK2 vs Euler: Phase Space
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(11, 3.5))
theta = np.linspace(0, 2 * np.pi, 200)
ax1.plot(np.cos(theta), -np.sin(theta), 'k--', lw=2)
ax1.plot(y_euler[:, 0], y_euler[:, 1], 'r-', lw=0.3, alpha=0.6)
ax1.set(title='Euler: Spiral Out', xlabel='$x$', ylabel='$v$')
ax1.set_aspect('equal')
ax2.plot(np.cos(theta), -np.sin(theta), 'k--', lw=2)
ax2.plot(y_rk2[:, 0], y_rk2[:, 1], 'b-', lw=0.5, alpha=0.7)
ax2.set(title='RK2: Much Tighter', xlabel='$x$', ylabel='$v$')
ax2.set_aspect('equal')
plt.tight_layout()
plt.show()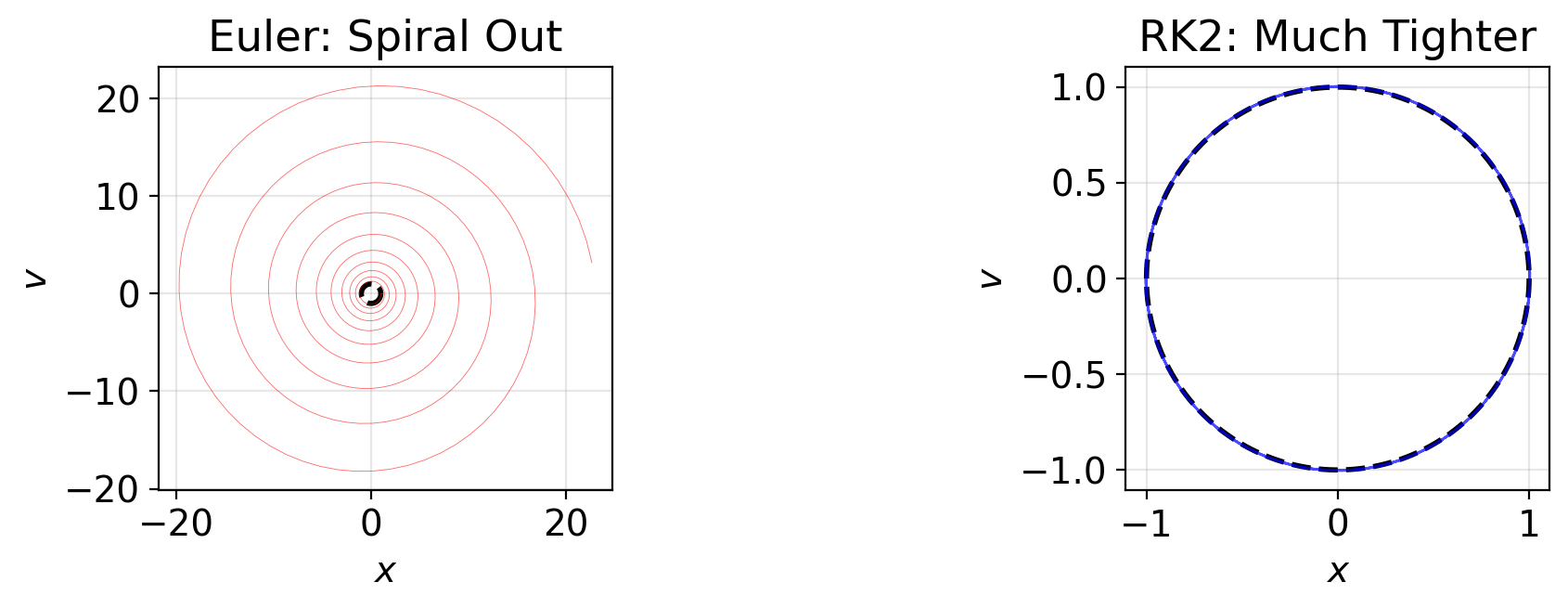
RK2 vs Euler: Energy
E_rk2 = 0.5 * (y_rk2[:, 0]**2 + y_rk2[:, 1]**2)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 3))
# Left: both on same scale
ax1.plot(t_euler, E_euler, 'r-', lw=1.5, label='Euler')
ax1.plot(t_rk2, E_rk2, 'b-', lw=1.5, label='RK2')
ax1.axhline(0.5, color='k', ls='--', lw=1)
ax1.set(xlabel='Time', ylabel='Energy $E$', title='Full Scale')
ax1.legend()
# Right: zoom on RK2
ax2.plot(t_rk2, E_rk2 - 0.5, 'b-', lw=1.5)
ax2.axhline(0, color='k', ls='--', lw=1)
ax2.set(xlabel='Time', ylabel='$E - E_0$', title='RK2 Energy Error (Zoomed)')
plt.tight_layout()
plt.show()
print(f"Euler final energy error: {abs(E_euler[-1] - 0.5):.1f}")
print(f"RK2 final energy error: {abs(E_rk2[-1] - 0.5):.2e}")
print(f"RK2 is {abs(E_euler[-1] - 0.5) / abs(E_rk2[-1] - 0.5):.0f}x better")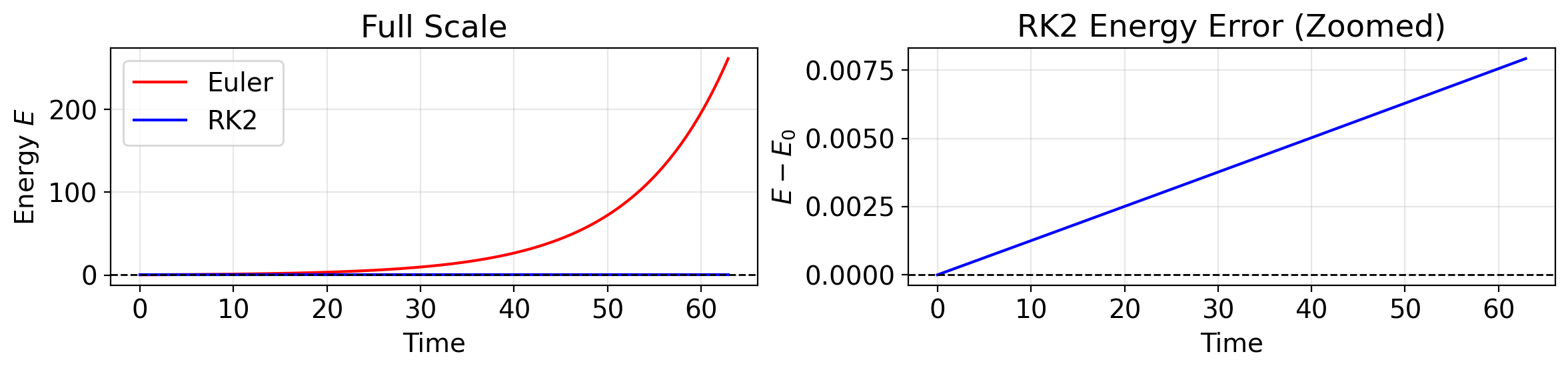
Euler final energy error: 260.8
RK2 final energy error: 7.92e-03
RK2 is 32908x betterRK2 is vastly better. But it still drifts. Over millions of timesteps — the kind you’ll run for Project 2 — that drift adds up. Is there something better?
