How do we transform vague beliefs into rigorous inference?
Core Question: How do we transform statements like “this star probably has little dust” into a mathematical framework that can connect observations to physical parameters under uncertainty?
Observable \(\to\) Model \(\to\) Inference roadmap
Observable: We measure quantities like apparent magnitude, color, spectrum, and variability period.
Model: We build a forward model that predicts those observables from physical parameters like distance, extinction, luminosity, or metallicity.
Inference: We use probability theory to update what we believe about those physical parameters given the data we actually observed.
This section develops the mathematical language that makes that pipeline possible.
2.1 Probability as Extended Logic
Priority - 🔴 Essential:
Deductive Logic Reasoning from premises to certain conclusions. If A is true and A implies B, then B is true. No uncertainty.
Plausibility Reasoning Extending logic to handle degrees of belief. If A makes B more plausible and A is somewhat plausible, then B becomes more plausible.
Cox’s Theorems Mathematical proof that probability theory is the UNIQUE extension of Boolean logic to handle uncertainty consistently.
What Are We Actually Doing? Epistemology
At its core, this section is about epistemology — the study of how we know things — because astronomy almost never gives us the physical quantities we care about directly.
We do not directly observe stellar mass, distance, age, or composition. We do observe light curves, spectra, colors, images, and apparent brightness.
That means astronomy always begins with an observable, then requires a model connecting those observables to physical reality, and finally demands inference to determine which physical explanations are most plausible.
Every scientific conclusion we make is therefore an inference: a statement about reality built from incomplete and uncertain information. The real question is: How should a rational scientist update knowledge in the presence of uncertainty? Classical logic cannot answer that question. Logic tells us what is certainly true. Science operates in a regime where almost nothing is certain. We need a framework that extends logic to handle degrees of belief without becoming inconsistent. That is the problem Cox set out to solve.
The Limits of True and False
Classical logic, the foundation of mathematics since Aristotle, deals in absolutes. A statement is either true or false. A star either has dust extinction or it doesn’t. But astronomy rarely gives us that kind of certainty. When we observe a reddened star, we cannot conclude with certainty that the star lies behind dust. The reddening could be intrinsic because the star is cool, it could be due to dust, it could reflect measurement error, or it could be some combination.
Consider the logical chain an astronomer faces:
If a star is behind dust, it will appear reddened (TRUE)
This star appears reddened (TRUE)
Therefore… what?
Classical logic fails here because it has no language for graded support. It can represent certainty, but not the intermediate state that dominates science: evidence that supports a claim without proving it. The star might be behind dust, but it might also be intrinsically red. A scientist needs to say something like: “the reddening increases the plausibility that the star is behind dust, but it does not prove it.” That is exactly the gap between deductive logic and scientific inference. Probability enters here not as a convenient tool, but as a necessity.
Probability: The Language of Plausible Reasoning
In the 1940s, physicist Richard Cox asked a more demanding question than “How should we use probability?” He asked: What rules must any rational system of belief obey if it is going to reason consistently under uncertainty? Under Cox’s assumptions about rational consistency, the rules of plausible reasoning are isomorphic to probability theory. In that sense, probability is not just a convenient tool. It is the unique consistent extension of Boolean logic to uncertain reasoning.
Cox started with desiderata (requirements) that any system of plausible reasoning should satisfy:
Degrees of Plausibility: Propositions have degrees of plausibility, represented by real numbers
Consistency: If a conclusion can be reached in multiple ways, all ways must give the same answer
Correspondence: In the limit of certainty, plausible reasoning must reduce to deductive logic
Universality: The system should handle any proposition we can state
From just these requirements — which seem almost too basic to be powerful — Cox proved that plausible reasoning MUST follow the rules of probability theory. Not “should” or “could” — MUST.
Important🎯 Cox’s Profound Result
The rules of probability aren’t human inventions — they’re mathematical necessities. Any system for reasoning under uncertainty that violates probability theory will lead to inconsistencies.
This means when we use probability in astronomy, we’re not making an arbitrary methodological choice. We’re using the unique consistent extension of logic to handle uncertainty.
The rules that emerge:
Sum Rule: P(A or B) = P(A) + P(B) - P(A and B)
Product Rule: \(P(A \text{ and } B) = P(A \mid B) \times P(B)\)
Bayes’ Theorem: Follows directly from the product rule
These aren’t axioms we choose — they’re theorems that follow from consistency. Probability is not just a tool for uncertain science. It is the only consistent epistemology for uncertainty.
From Astronomical Intuition to Mathematical Probability
Astronomers have always thought probabilistically, even before formalizing it. When Henrietta Leavitt said “these stars are probably at the same distance,” she was expressing a degree of belief. When modern astronomers say “this galaxy probably contains dark matter,” they’re doing plausible reasoning. Probability theory just makes this reasoning mathematically rigorous.
Let’s see how astronomical statements become probabilities:
Qualitative Statement\(\to\)Probability Statement
“This star is probably nearby” \(\to\)\(P(d < 100~\text{pc}) = 0.8\)
“Little dust in this direction” \(\to\)\(P(A_V < 0.1~\text{mag}) = 0.9\)
Each transformation takes vague intuition and makes it precise. The numbers aren’t arbitrary — they encode our accumulated knowledge from centuries of observations.
The Cepheid Example: From Logic to Probability
Before writing probabilities, we should state the inferential problem clearly:
Observed: period, apparent magnitude, colors, and their uncertainties
Unknown: distance, extinction, and possibly metallicity
Goal: infer which combinations of physical parameters are most compatible with the observations
Classical logic cannot solve this because the data do not determine a unique conclusion. Probability gives us a way to represent and update degrees of support across many possible physical explanations.
Let’s apply this to our running Cepheid example. Using classical logic:
What we know for certain:
The star’s brightness varies periodically (TRUE)
The period is 5.366 days (TRUE)
Longer-period Cepheids are intrinsically brighter (TRUE from P-L relation)
What we can’t deduce with certainty:
The star’s distance (depends on intrinsic brightness)
The amount of dust extinction (degenerate with distance)
Whether it follows the standard P-L relation (metallicity effects?)
Enter probability:
\(P(\text{follows standard } P\text{-}L | \text{ in Milky Way}) = 0.95\)
\(P(\text{distance} = d \, | \text{ apparent mag} = m, \text{ period} = P) =\) [needs Bayes!]
Probability extends our logical reasoning to handle these uncertainties systematically.
Note🌟 Historical Note: Laplace’s Principle
Pierre-Simon Laplace, the “French Newton,” independently developed probability theory for astronomy in the late 1700s. His principle of insufficient reason stated: without specific information favoring one possibility over another, assign equal probabilities.
Laplace used this to estimate the mass of Saturn from its satellites’ orbits, to predict the orbit of comets, and famously to calculate the probability that the sun will rise tomorrow (he got 1,826,214 to 1 based on historical records).
His work showed that probability isn’t just about games of chance — it’s the mathematical framework for scientific inference.
Why Not Other Systems?
You might wonder: Why probability? Couldn’t we use fuzzy logic, possibility theory, or some other framework? Cox’s theorems say no — if we want consistency, we’re forced to use probability.
Here’s what happens with alternatives:
Fuzzy Logic: Handles vagueness (“very hot star”) but not uncertainty about facts Interval Arithmetic: Gives ranges but loses information about likelihood within the range Possibility Theory: Lacks the mathematical structure needed for updating with evidence
Only probability theory provides: - Consistent updating with new information (Bayes’ theorem) - Proper handling of correlations between variables - Natural incorporation of measurement uncertainties - Recovery of deductive logic in the limit of certainty
This uniqueness is profound. It means that aliens doing astronomy would use the same probability theory we do — not because they learned it from us, but because mathematics forces it on any consistent reasoner.
Important
💡 What We Just Learned At the Observable \(\to\) Model \(\to\) Inference level, this section gives us the language of uncertainty. Probability theory isn’t one option among many for handling uncertainty — it’s the unique consistent extension of logic. It turns vague statements about plausibility into precise mathematical expressions that can be combined, updated, and tested.
Note🎯 From Aristotle to Bayes: The Evolution of Logic
Show code
flowchart TD A["Observations (Data)<br>brightness, spectra, variability"] -->|"We observe data"| B["Goal: Infer Physical Parameters<br>distance, mass, composition"] A --> C["Classical Logic<br>True / False Reasoning"] C -->|"Fails under uncertainty"| D["Inference is impossible with logic alone"] D --> E["Epistemology<br>How should we reason about uncertain knowledge?"] E --> F["Cox's Theorems<br>Consistency requirements for rational belief"] F --> G["Probability Theory<br>UNIQUE extension of logic"] G --> H["Physics gives forward model:<br>P(data | parameters)<br>(Likelihood)"] H --> I["We want inverse:<br>P(parameters | data)"] I --> J["Bayes' Theorem<br>P(parameters|data) proportional to P(data|parameters) P(parameters)"] J --> K["Posterior:<br>Updated knowledge about reality"] style D fill:#ffe6e6 style G fill:#e6ffe6 style J fill:#e6f0ff style K fill:#fff5cc
flowchart TD
A["Observations (Data)<br>brightness, spectra, variability"] -->|"We observe data"| B["Goal: Infer Physical Parameters<br>distance, mass, composition"]
A --> C["Classical Logic<br>True / False Reasoning"]
C -->|"Fails under uncertainty"| D["Inference is impossible with logic alone"]
D --> E["Epistemology<br>How should we reason about uncertain knowledge?"]
E --> F["Cox's Theorems<br>Consistency requirements for rational belief"]
F --> G["Probability Theory<br>UNIQUE extension of logic"]
G --> H["Physics gives forward model:<br>P(data | parameters)<br>(Likelihood)"]
H --> I["We want inverse:<br>P(parameters | data)"]
I --> J["Bayes' Theorem<br>P(parameters|data) proportional to P(data|parameters) P(parameters)"]
J --> K["Posterior:<br>Updated knowledge about reality"]
style D fill:#ffe6e6
style G fill:#e6ffe6
style J fill:#e6f0ff
style K fill:#fff5cc
The Key Insight: Probability is not one option among many. It is the only consistent extension of logic to uncertainty, and Bayes’ theorem is the rule that turns that logic into scientific updating.
2.2 Likelihood: Encoding Physics as Probability
Priority: 🔴 Essential
Likelihood \(L(\theta)\) The likelihood is the function of the parameters defined by the conditional probability of the observed data:
\[L(\theta) \propto P(\text{data} \mid \theta)\]
For fixed observed data, the likelihood tells us which parameter values make those data more or less compatible with the model. It is not the posterior and it is not the probability that the parameters are correct.
Generative Model A model that can generate simulated data given parameters. The likelihood evaluates how probable the actual data would be under this generative process.
Noise Model The statistical description of measurement errors and intrinsic scatter. Often Gaussian, but can be Poisson (counts), Student-t (outliers), or others.
The Direction That Physics Gives Us
In the Observable \(\to\) Model \(\to\) Inference framework, the likelihood is the step where the model turns physical parameters into predicted observables with an explicit uncertainty model.
Physics naturally runs forward — from causes to effects, from parameters to observations. If we know a star’s temperature, we can predict its spectrum. If we know a Cepheid’s period and intrinsic brightness, we can predict its apparent magnitude at any distance. This forward direction is what physics provides, and it’s encoded in the likelihood function.
But here’s the critical insight that confuses many: The likelihood is NOT the probability of the parameters. It’s the probability of the data given the parameters. This distinction is subtle but fundamental.
Consider measuring a Cepheid’s brightness: - Forward (Physics): Given \(M = -3.5\) and \(d = 2.5~\text{Mpc}\), predict \(m = 21.5\) - Inverse (Inference): Given \(m = 21.5 \pm 0.1\) and \(P = 5.4~\text{days}\), infer \(d\)
The likelihood lives in the forward-model direction:
start with a hypothetical physical state,
predict what data that state would generate,
ask whether the observed data would be plausible under that hypothesis.
So the likelihood asks:
If the distance were 2.5 Mpc, how probable is it that we would observe \(m = 21.5\)?
That is fundamentally different from the inferential question:
Given that we observed \(m = 21.5\), how plausible is 2.5 Mpc?
The first is likelihood. The second requires Bayes’ theorem.
Building a Likelihood from Physics
Let’s construct a real likelihood function for our Cepheid. We start with the physics — the Period-Luminosity relation discovered by Leavitt:
The Physics Model: \[M_V = -2.43(\log_{10} P - 1) - 4.05\]
where M_V is absolute V-band magnitude and P is period in days.
Adding Distance: The distance modulus relation connects intrinsic and apparent brightness: \[m - M = 5\log_{10}(d) - 5\]
This is our deterministic model — given P and d, we predict m. But observations aren’t perfect…
From Deterministic Model to Probabilistic Likelihood
Real measurements have uncertainties. Our CCD has read noise, the atmosphere scintillates, and Cepheids have intrinsic scatter in their P-L relation. We need to transform our deterministic model into a probability distribution.
Step 2: Choose a noise model From the Statistical Thinking module, we learned about the Central Limit Theorem — many small random effects sum to a Gaussian distribution. Both measurement errors and intrinsic scatter arise from many small effects, so we use a Gaussian noise model.
where we’ve added extinction A_V to our model (making it more realistic).
The Likelihood in Practice
def cepheid_likelihood(params, observations):""" Likelihood for Cepheid distance measurement. Physics model + measurement uncertainty = likelihood """ distance, extinction = params # What we want to infer period, apparent_mag, mag_error = observations # What we measured# Physics: Period-Luminosity relation (Leavitt Law) absolute_mag =-2.43* (np.log10(period) -1) -4.05# Physics: Distance modulus distance_modulus =5* np.log10(distance) -5# Physics: Extinction dims the star predicted_mag = absolute_mag + distance_modulus + extinction# Statistics: Gaussian noise model intrinsic_scatter =0.15# Cepheids aren't perfect standard candles total_sigma = np.sqrt(mag_error**2+ intrinsic_scatter**2)# The likelihood: How probable is our observation given these parameters? residual = apparent_mag - predicted_mag log_likelihood =-0.5* (residual/total_sigma)**2- np.log(total_sigma * np.sqrt(2*np.pi))return np.exp(log_likelihood)
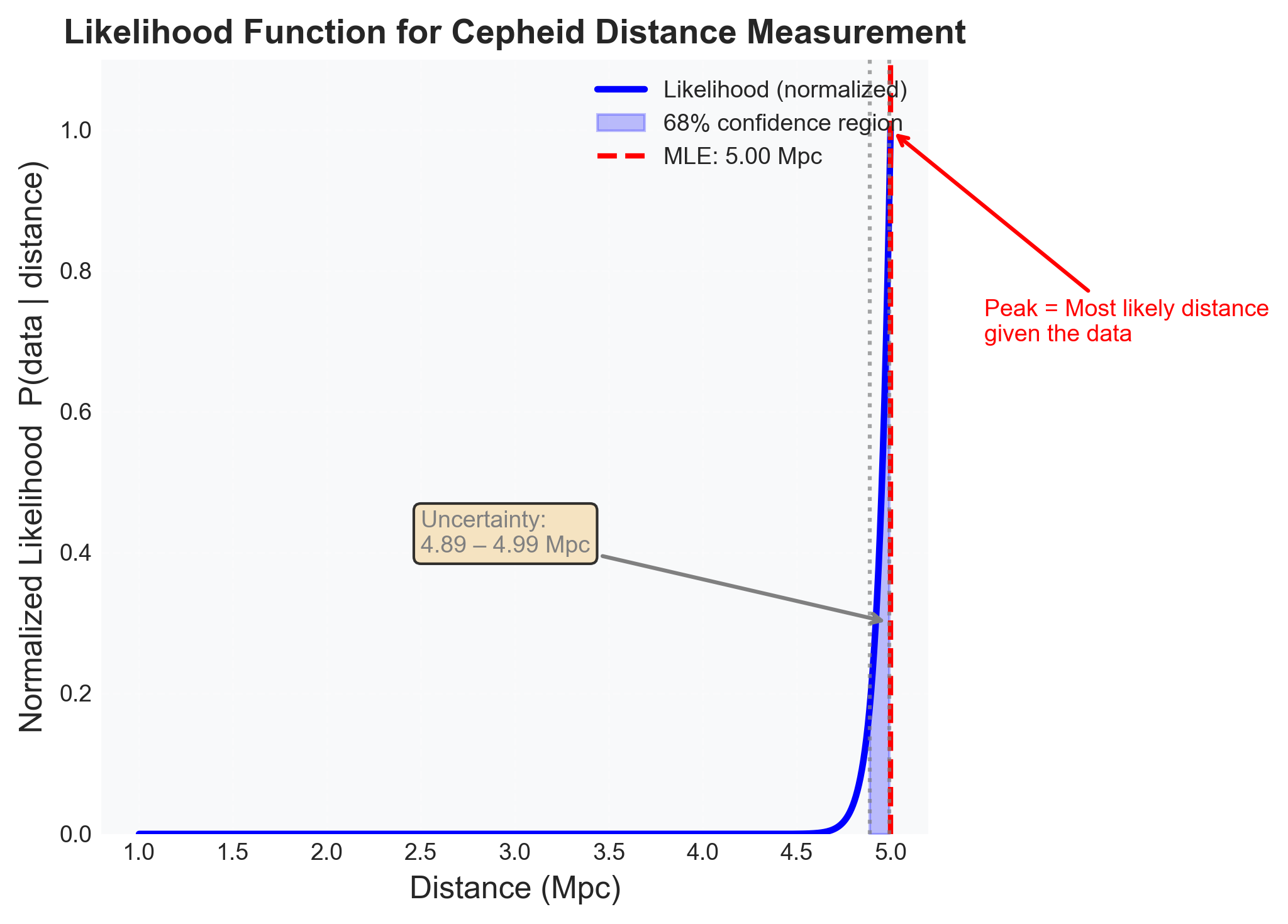
Figure 1: Likelihood function for Cepheid distance measurement. This figure shows how the likelihood \(P(\text{data}\mid d)\) quantifies the compatibility between our observations and different distance hypotheses. The normalized likelihood peaks at the maximum-likelihood estimate \(d \approx 5.00~\text{Mpc}\), the distance most consistent with the observed apparent magnitude \(m = 25.3 \pm 0.05~\text{mag}\) and period \(P = 10~\text{days}\). The shaded \(68\%\) region spans approximately \(4.89\)–\(4.99~\text{Mpc}\). The narrow width shows that precise photometry and a calibrated period-luminosity relation strongly constrain distance. This is not the probability that the distance is correct; it is the probability of the observed data under each distance hypothesis.
Common Likelihood Pitfalls
Pitfall 1: Forgetting intrinsic scatter If you only include measurement error, you’ll be overconfident. Real astronomical objects have intrinsic variation that must be included in the likelihood.
Pitfall 2: Assuming Gaussian errors From Statistical Thinking, we know the CLT gives us Gaussians for many small effects. But what about outliers? Cosmic rays? Variable stars misclassified as Cepheids? Real data often has heavy tails, requiring robust likelihoods (like Student-t distributions).
Pitfall 3: Ignoring correlations If you observe multiple Cepheids with the same telescope, their measurements share systematic errors. The likelihood needs the full covariance matrix, not just individual error bars.
ImportantFrom Scalar to Matrix Likelihoods
So far we have written likelihoods for a single measurement with independent Gaussian error:
Real datasets have \(n\) data points with correlated uncertainties described by an \(n \times n\) covariance matrix \(\mathbf{C}\). The multivariate Gaussian log-likelihood generalizes to:
where \(\mathbf{r}\) is the residual vector \(r_i = y_i^\mathrm{obs} - y_i^\mathrm{model}(\theta)\). The matrix \(\mathbf{C}^{-1}\) weights each residual by its uncertainty and accounts for correlations between data points. Off-diagonal elements of \(\mathbf{C}\) encode shared systematic errors — for example, a calibration uncertainty that shifts all measurements in the same direction.
Implementation tip: Never explicitly compute \(\mathbf{C}^{-1}\). Instead, use Cholesky factorization: decompose \(\mathbf{C} = \mathbf{L}\mathbf{L}^\top\) (where \(\mathbf{L}\) is lower triangular), then solve \(\mathbf{L}\mathbf{x} = \mathbf{r}\) by forward substitution. The quadratic form becomes \(\mathbf{r}^\top\mathbf{C}^{-1}\mathbf{r} = \mathbf{x}^\top\mathbf{x}\). In NumPy:
L = np.linalg.cholesky(C) # Factor oncex = np.linalg.solve(L, residuals) # Solve per evaluationchi2 = x @ x # Fast dot product
This is numerically stable, avoids matrix inversion, and will be essential for Project 4.
Pitfall 4: Confusing likelihood with posterior Remember: likelihood is \(P(\text{data} \mid \text{parameters})\), not \(P(\text{parameters} \mid \text{data})\). Mixing these up leads to incorrect inferences.
Wrong reasoning sounds like this: “The likelihood peaks at 5 Mpc, so the star is probably at 5 Mpc.” That is not yet justified. A likelihood peak identifies which parameter values make the observed data most compatible with the forward model. It is not a posterior statement about what is most plausible after accounting for prior knowledge and normalization over parameter space.
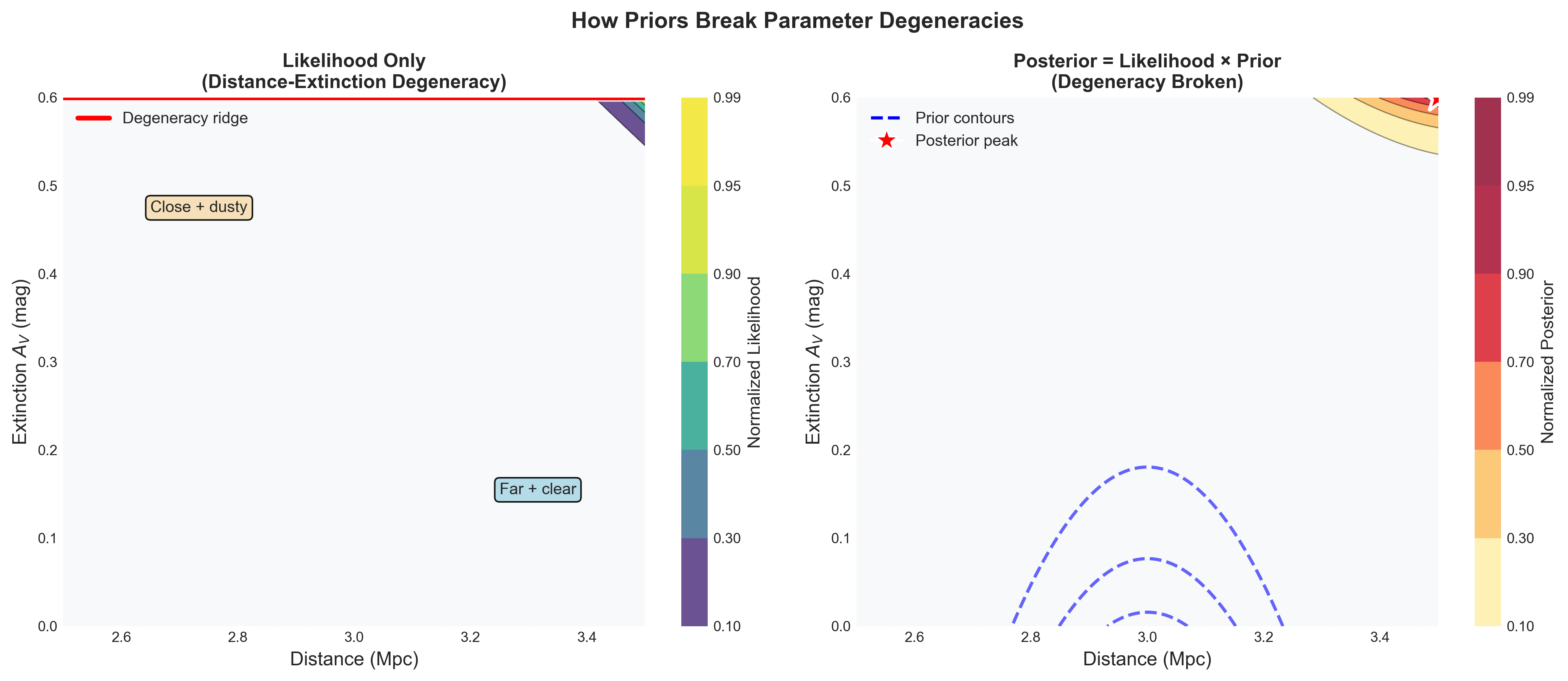
Figure 2: How priors break parameter degeneracies in 2D likelihood spaces. The left panel shows a distance-extinction degeneracy ridge: many parameter combinations fit the data equally well. A star could be close and dusty, with \(d \approx 2.6~\text{Mpc}\) and \(A_V \approx 0.5~\text{mag}\), or far and nearly clear, with \(d \approx 3.4~\text{Mpc}\) and \(A_V \approx 0.1~\text{mag}\). The likelihood alone cannot distinguish these scenarios because dust extinction and distance both affect apparent brightness. The right panel adds physically motivated priors: a Gaussian prior on distance from previous measurements, \(3.0 \pm 0.15~\text{Mpc}\), and an exponential prior on extinction favoring low \(A_V\). The posterior then concentrates near \(d \approx 3.0~\text{Mpc}\) and \(A_V \approx 0.2~\text{mag}\). Priors are powerful here because they encode real astronomical knowledge that breaks degeneracies the data alone cannot resolve.
The Deep Connection to Information Theory
Fisher Information A measure of how much information about parameters is contained in the data. High curvature in the log-likelihood means high information — small changes in parameters cause large changes in probability.
The likelihood encodes information about parameters contained in the data. In information theory terms, it quantifies how “surprised” we should be by the observations given different parameter values. High likelihood = unsurprising (expected given the parameters). Low likelihood = surprising (unexpected given the parameters).
The width of the likelihood function tells us about information content:
Narrow likelihood: Data strongly constrains parameters (high information)
Broad likelihood: Data weakly constrains parameters (low information)
Flat likelihood: Data provides no constraint (zero information)
For our Cepheid, a precise brightness measurement gives a narrow likelihood in distance. A noisy measurement gives a broad likelihood. This width — the Fisher information — fundamentally limits how well we can measure distance regardless of our analysis method.
Connection to Statistical Thinking
Remember from the Statistical Thinking module that temperature is the width of the velocity distribution? The likelihood plays a similar role — it encodes the “width” of possible observations given parameters. Just as temperature describes the spread in molecular velocities, the likelihood describes the spread in possible observations.
The Central Limit Theorem from Statistical Thinking justifies our Gaussian likelihoods. When many small effects contribute to measurement error, their sum approaches a Gaussian. This is why Gaussian likelihoods are ubiquitous in astronomy — not by choice, but by mathematical necessity.
Note📚 Philosophical Insight: Models All the Way Down
The likelihood embodies our complete model of the measurement process:
The physics (\(P\)-\(L\) relation)
The instrument (measurement uncertainty)
The astrophysics (intrinsic scatter)
The statistics (noise distribution)
Each level involves models and assumptions. The P-L relation assumes Cepheids are standard candles. The measurement uncertainty assumes we’ve calibrated correctly. The intrinsic scatter assumes all Cepheids drawn from the same population.
This isn’t a weakness — it’s honesty. By making our assumptions explicit in the likelihood, we can test them, improve them, and quantify how they affect our conclusions.
Important
💡 What We Just Learned At the Observable \(\to\) Model \(\to\) Inference level, the likelihood is the model step. The likelihood \(P(\text{data}\mid \text{parameters})\) encodes physics plus measurement uncertainty and runs in the forward direction — from parameters to observations. It is not the probability that the parameters are correct; it is the probability of the observed data under a parameter hypothesis.
Note🔗 Connection to Module 1: Why Gaussian Likelihoods?
Remember the Central Limit Theorem from Statistical Thinking? It tells us that sums of many independent random effects converge to Gaussian distributions.
In our Cepheid likelihood:
Photon noise: Many photons arriving randomly \(\to\) approximately Gaussian
Detector read noise: Many thermal electrons \(\to\) approximately Gaussian
Atmospheric scintillation: Many turbulent cells \(\to\) approximately Gaussian
Intrinsic Cepheid scatter: Many small stellar physics effects \(\to\) approximately Gaussian
The CLT isn’t just abstract math — it justifies our Gaussian likelihoods. When we write:
We’re using the CLT’s guarantee that measurement errors are Gaussian!
From Module 1: Distributions characterize uncertainty Now in Module 5: Those distributions become likelihoods
Tip🤔 Pause and Reflect: Understanding Likelihood
Before moving forward, test your understanding:
Directionality: Why is P(data|parameters) easier to write than P(parameters|data)? What does physics give us naturally?
Not Probability of Parameters: Explain to a friend why the likelihood ≠ probability of parameters being correct. Use the Cepheid example.
Noise Models: We used Gaussian noise. When would this be wrong? (Hint: Think about outliers, cosmic rays, misclassified stars)
Information Content: Two Cepheids have the same brightness but different uncertainties: \(\pm 0.02~\text{mag}\) vs. \(\pm 0.20~\text{mag}\). Which provides more information about distance? Why?
If these questions feel uncomfortable, revisit Section 2.2. The likelihood is the bridge between physics and inference — understanding it is crucial.
2.3 Priors: Quantifying What We Already Know
Priority: 🔴 Essential
Prior \(P(\theta)\) The probability distribution representing our knowledge about parameters before seeing the current data. Encodes physical constraints, previous measurements, and theoretical expectations.
Informative Prior A prior that significantly constrains parameters based on previous knowledge. Example: Using Cepheid calibration from HST for distance ladder.
Uninformative Prior A prior that attempts to encode ignorance, letting data dominate. Never truly uninformative — even “uniform” makes assumptions.
In the Observable \(\to\) Model \(\to\) Inference framework, the prior represents what we already know about the unknown model parameters before confronting the current observations.
The Knowledge We Bring to Every Observation
No observation is interpreted in a vacuum. When Henrietta Leavitt observed Cepheids in the Small Magellanic Cloud, she brought the belief that these stars were roughly equidistant. When Edwin Hubble used Cepheids to measure the distance to Andromeda, he brought Leavitt’s P-L calibration. Every measurement builds on previous knowledge — this is what priors formalize.
Consider what you implicitly know before observing tonight’s Cepheid:
Distances are positive (\(d > 0\))
It’s probably in our galaxy (\(d < 30~\text{kpc}\)) or a nearby galaxy (\(d < 10~\text{Mpc}\))
Extinction only reddens, never bluens (\(A_V \geq 0\))
Most sightlines have modest extinction (\(A_V < 2~\text{mag}\))
The \(P\)-\(L\) relation has limited scatter (\(\sigma \approx 0.15~\text{mag}\))
This isn’t subjective opinion — it’s accumulated astronomical knowledge from centuries of observations. Priors transform this knowledge into mathematical form.
Types of Priors in Astronomy
Physical Constraint Priors These encode fundamental physical limits:
def distance_prior(d):"""Distance must be positive"""return1.0if d >0else0.0def extinction_prior(A_V):"""Extinction can only redden light"""return1.0if A_V >=0else0.0def mass_prior(M):"""Stars have limited mass range"""if0.08< M <150: # Solar massesreturn1.0else:return0.0
Population Priors These encode knowledge about astronomical populations:
The Initial Mass Function (IMF) tells us most stars are low-mass: \[P(M) \propto M^{-2.35} \quad \text{(Salpeter IMF)}\]
The galactic extinction distribution from dust maps: \[P(A_V | l, b) = \text{Value from Schlegel dust maps}\]
The period distribution of Cepheids: \[P(\log P) \approx \mathcal{N}(1.0, 0.5) \quad \text{(days)}\]
Hierarchical Priors These capture how individual objects relate to populations:
# Individual Cepheid draws from populationpopulation_mean_M =-2.43* (log_P -1) -4.05population_scatter =0.15individual_M ~ Normal(population_mean_M, population_scatter)# Population parameters themselves have priorspopulation_scatter ~ HalfNormal(0.2) # Must be positive, probably small
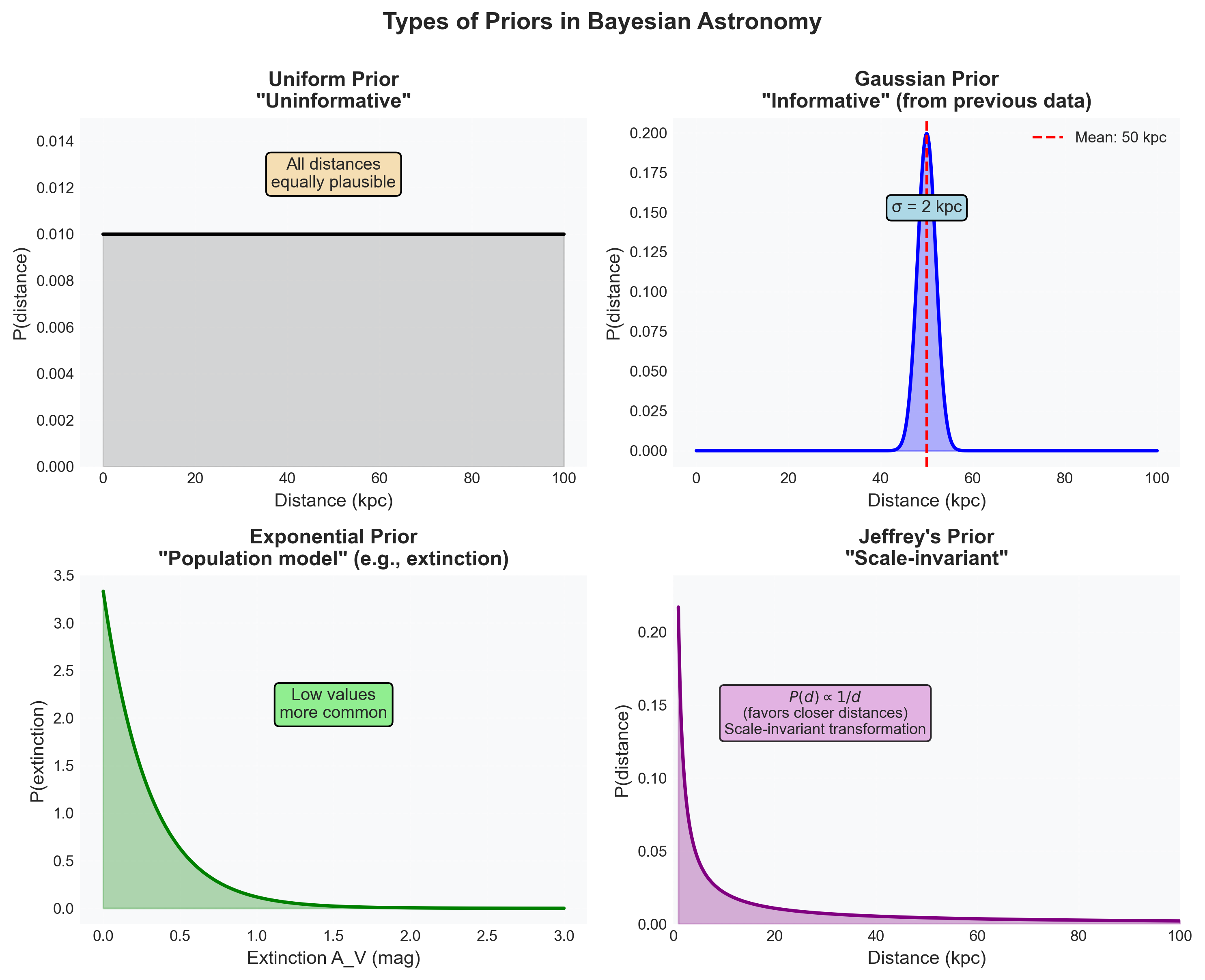
Figure 3: Four fundamental types of priors in Bayesian astronomy. This figure illustrates how different kinds of prior knowledge are encoded mathematically. A uniform prior treats all distances in a fixed interval as equally plausible. A Gaussian prior encodes previous measurements, such as a galaxy distance of \(50 \pm 2~\text{kpc}\). An exponential prior describes population structure, for example low-extinction sightlines being more common than high-extinction ones. A Jeffreys prior uses \(P(d) \propto 1/d\) to remain scale-invariant, so changing from \(1\) to \(2~\text{kpc}\) is as significant as changing from \(50\) to \(100~\text{kpc}\). Each prior type serves a different inferential purpose and makes assumptions such as \(d > 0\) explicit and testable.
The Prior Controversy: Subjectivity vs. Objectivity
Critics of Bayesian inference often focus on priors: “Aren’t they subjective? Different priors give different answers!” This criticism misunderstands what priors represent.
Priors are not arbitrary personal opinions. They are mathematical representations of information already available before analyzing the current dataset.
That information may come from:
Physical constraints
Previous measurements
Population statistics
Instrument knowledge
Theoretical structure
Yes, different priors give different posteriors. But this is a feature, not a bug! If you have better prior information (say, from Gaia parallaxes), you SHOULD get better distance estimates than someone using vague priors.
Important🎭 The Objectivity Illusion
Even “objective” frequentist methods use implicit priors:
Maximum Likelihood: Implicitly uses a uniform prior Least Squares: Assumes Gaussian errors with known variance Periodogram: Assumes sinusoidal signals
The Bayesian approach makes priors explicit, allowing scrutiny and improvement. This transparency is more scientific than hiding assumptions in the method.
Constructing Priors for Cepheid Distance
Let’s build realistic priors for our Cepheid problem:
import numpy as npfrom scipy import statsclass CepheidPriors:""" Prior knowledge for Cepheid distance measurement. Encodes centuries of astronomical knowledge. """def__init__(self, galaxy='LMC'):self.galaxy = galaxydef distance_prior(self, d):""" Distance prior based on galaxy """ifself.galaxy =='LMC':# Previous measurements: 50 +/- 2 kpc# This is informative prior from decades of study mean_d =50000# parsecs sigma_d =2000return stats.norm.pdf(d, mean_d, sigma_d)elifself.galaxy =='M31':# Andromeda: 780 +/- 40 kpc mean_d =780000 sigma_d =40000return stats.norm.pdf(d, mean_d, sigma_d)else:# Unknown galaxy: use volume prior# P(d) proportional to d**2 for uniform space distributionif0< d <20e6: # Within 20 Mpcreturn d**2else:return0.0def extinction_prior(self, A_V, l, b):""" Extinction prior from dust maps and galactic latitude """# Higher extinction toward galactic plane scale_height =100# parsecsif A_V <0:return0.0# Extinction can't be negative# Exponential distribution with scale depending on latitude mean_extinction =0.1/ np.abs(np.sin(b * np.pi/180))return stats.expon.pdf(A_V, scale=mean_extinction)def metallicity_prior(self, Z, galaxy_type='spiral'):""" Metallicity affects P-L relation """if galaxy_type =='spiral':# Solar neighborhood metallicityreturn stats.norm.pdf(Z, loc=0.0, scale=0.2) # [Fe/H]elif galaxy_type =='elliptical':# Metal-richreturn stats.norm.pdf(Z, loc=0.3, scale=0.3)elif galaxy_type =='dwarf':# Metal-poorreturn stats.norm.pdf(Z, loc=-0.7, scale=0.4)
When Priors Matter Most
Priors have different impacts depending on data quality:
Strong Data, Weak Prior: Data dominates
100 Cepheids with precise measurements
Prior just excludes impossible values
Different reasonable priors \(\to\) similar posteriors
Weak Data, Strong Prior: Prior dominates
1 Cepheid with large uncertainty
Prior provides essential constraint
Different priors \(\to\) different posteriors
The Sweet Spot: Prior and data comparable
Few Cepheids with moderate precision
Prior helps break degeneracies
Optimal information combination
This is why priors matter so much in astronomy — we often have limited data and must leverage prior knowledge to make progress.
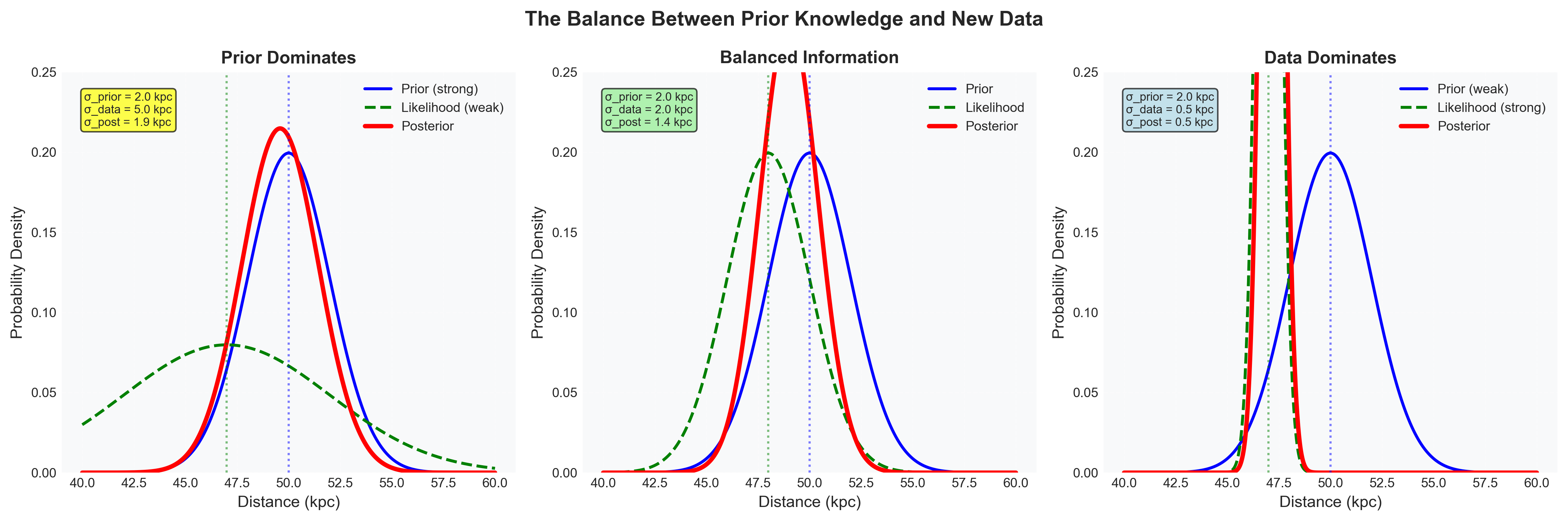
Figure 4: The balance between prior knowledge and new data determines posterior uncertainty. All panels start with the same informative Gaussian prior, centered at \(50~\text{kpc}\) with \(\sigma_\text{prior} = 2.0~\text{kpc}\), but differ in data quality. When the data are weak, with \(\sigma_\text{data} = 5.0~\text{kpc}\), the posterior stays close to the prior and little new information is gained. When prior and data have comparable precision, with \(\sigma_\text{data} = 2.0~\text{kpc}\), the posterior sits between them and becomes substantially narrower. When the data dominate, with \(\sigma_\text{data} = 0.5~\text{kpc}\), the posterior closely tracks the likelihood. The uncertainty combination follows \(1/\sigma_\text{post}^2 = 1/\sigma_\text{prior}^2 + 1/\sigma_\text{data}^2\). This is why priors matter most when observations are weak or only moderately constraining — exactly the regime where much of astronomy operates.
The Cosmic Distance Ladder as Hierarchical Priors
The entire cosmic distance ladder is a beautiful example of hierarchical Bayesian inference:
Parallax (direct measurement)
Prior: Uniform in space
Data: Gaia measurements
Posterior: Distance to nearby stars
Cluster Cepheids (first rung)
Prior: Cluster members share distance
Data: Periods and brightness
Posterior: P-L relation calibration
LMC Cepheids (second rung)
Prior: P-L calibration from clusters
Data: LMC Cepheid observations
Posterior: Distance to LMC
Distant Galaxies (third rung)
Prior: LMC distance and P-L relation
Data: Galaxy Cepheid observations
Posterior: Hubble constant
Each rung’s posterior becomes the next rung’s prior — a cascade of inference building from parallax to cosmology!
Note🪜 The Cosmic Distance Ladder: Bayesian Inference in Action
Show code
graph TD A["Parallax<br>Direct Measurement"] -->|"Posterior<br>becomes Prior"| B["Nearby Cepheids<br>Calibrate P-L Relation"] B -->|"P-L Calibration<br>becomes Prior"| C["LMC Cepheids<br>LMC Distance"] C -->|"LMC Distance<br>becomes Prior"| D["Distant Galaxy Cepheids<br>Hubble Constant"] D -->|"H0 Prior"| E["High-z Supernovae<br>Cosmology"] style A fill:#ffcccc style B fill:#ffe6cc style C fill:#ffffcc style D fill:#e6ffcc style E fill:#ccffcc
graph TD
A["Parallax<br>Direct Measurement"] -->|"Posterior<br>becomes Prior"| B["Nearby Cepheids<br>Calibrate P-L Relation"]
B -->|"P-L Calibration<br>becomes Prior"| C["LMC Cepheids<br>LMC Distance"]
C -->|"LMC Distance<br>becomes Prior"| D["Distant Galaxy Cepheids<br>Hubble Constant"]
D -->|"H0 Prior"| E["High-z Supernovae<br>Cosmology"]
style A fill:#ffcccc
style B fill:#ffe6cc
style C fill:#ffffcc
style D fill:#e6ffcc
style E fill:#ccffcc
Hierarchical Bayesian Inference: The entire cosmic distance ladder is a cascade of Bayesian updates, each rung’s posterior becoming the next rung’s prior!
Note🌟 Historical Note: Jeffreys and the Prior Revolution
Harold Jeffreys, a Cambridge geophysicist, revolutionized scientific inference in the 1930s-1960s. He developed “objective” priors that encode minimal information while respecting problem symmetries.
This prior is invariant under parameter transformations — if you reparameterize your problem, the prior transforms consistently. It’s as close to “objective” as priors can get.
Jeffreys applied Bayesian methods to test continental drift (which he incorrectly rejected!), estimate earthquake locations, and determine planetary masses. His work showed that priors needn’t be subjective — they can encode symmetries and invariances in the problem structure.
Connection to Statistical Thinking
From the Statistical Thinking module, we learned about marginalization — integrating over variables we don’t care about. Priors enable this:
The prior on extinction \(A_V\) lets us marginalize it out if we only care about distance. Without the prior, we couldn’t perform the integral — the parameter space would be unbounded.
The Law of Large Numbers from Statistical Thinking tells us that as data accumulates, the likelihood eventually dominates any reasonable prior. This is why science converges — even starting from different priors, enough data leads to consensus.
Important
💡 What We Just Learned At the Observable \(\to\) Model \(\to\) Inference level, priors formalize what we already know about the unknown parameters before confronting the current data. They are not arbitrary opinions; they are mathematical encodings of physical constraints, empirical patterns, and previous measurements. Priors matter most when data is limited — exactly the regime where much of astronomy operates.
Note🔗 Connection to Module 1: Marginalization Enables Focusing
From Statistical Thinking, we learned about marginalization—integrating over variables we don’t care about to focus on what matters.
Example: Cepheid distance with uncertain extinction
We want P(d|data), but our model has two parameters: distance d and extinction A_V.
The prior on \(A_V\) enables this integral! Without \(P(A_V)\), the integral would be unbounded — we couldn’t marginalize.
From Module 1: Marginalization lets us focus on relevant variables Now in Module 5: Priors make marginalization possible
This is why priors aren’t just philosophical — they’re computationally necessary for handling nuisance parameters.
Tip🤔 Pause and Reflect: The Role of Priors
Priors are where students often get skeptical. Test your understanding:
Objective Information: Give three examples of priors that encode objective astronomical knowledge, not subjective opinion.
Prior Strength: When does the prior matter most? When does data dominate regardless of prior? Use the strong/weak data framework from the text.
Distance Ladder: Explain how the cosmic distance ladder is hierarchical Bayesian inference. How does each rung’s posterior become the next rung’s prior?
The Controversy: A friend says “Priors are subjective, so Bayesian inference isn’t objective science.” How do you respond using concepts from this section?
Strong opinions about priors often indicate they haven’t been thought through deeply. The questions above should clarify their role.
The posterior equals likelihood times prior divided by evidence. The mathematical rule for updating beliefs with data.
Evidence \(P(D)\) The probability of observing the data marginalized over all parameters. Also called the marginal likelihood. Usually ignored for parameter estimation but crucial for model comparison.
In the Observable \(\to\) Model \(\to\) Inference framework, Bayes’ theorem is the step that converts the forward model plus prior knowledge into an updated distribution over the unknown parameters after seeing the data.
The Counting Argument: Bayes from First Principles
Before writing equations, let’s derive Bayes’ theorem using simple counting — an argument so elementary it seems almost trivial, yet it gives us the most profound theorem in inference.
Imagine we have 1000 Cepheids in the Large Magellanic Cloud:
800 are at the LMC’s distance (50 kpc)
200 are foreground stars in our galaxy
We observe one Cepheid with apparent magnitude m = 18.5. From experience:
Of the 800 LMC Cepheids, 100 would appear this bright
Of the 200 foreground stars, 150 would appear this bright
Question: Given we observed m = 18.5, what’s the probability it’s in the LMC?
Counting solution:
Total Cepheids with m = 18.5: 100 + 150 = 250
LMC Cepheids with m = 18.5: 100
Probability = 100/250 = 0.4
Now let’s write this mathematically:
\[P(\text{LMC} | m=18.5) = \frac{\text{Number at LMC AND m=18.5}}{\text{Total number with m=18.5}}\]
\(P(\theta \mid D)\): Posterior - what we want (parameters given data)
\(P(D \mid \theta)\): Likelihood - what physics gives us (data given parameters)
\(P(\theta)\): Prior - what we knew before
\(P(D)\): Evidence - normalization ensuring probabilities sum to 1
Each piece has a role:
Likelihood: How well do these parameters explain the data?
Prior: How plausible were these parameters before seeing data?
Posterior: How plausible are these parameters after seeing data?
Evidence: What’s the total probability of seeing this data?
Why Multiplication? The Product Rule
Bayes’ theorem multiplies likelihood and prior because it follows directly from the product rule of probability. The joint probability \(P(\theta, D) = P(D|\theta)P(\theta) = P(\theta|D)P(D)\); solving for \(P(\theta|D)\) gives Bayes’ theorem. No independence assumption is needed — this is an identity.
The prior and likelihood represent different types of information:
Prior: What we knew before collecting this data (e.g., “probably ~50 kpc”)
Likelihood: What the new data tells us (e.g., “consistent with 48 kpc”)
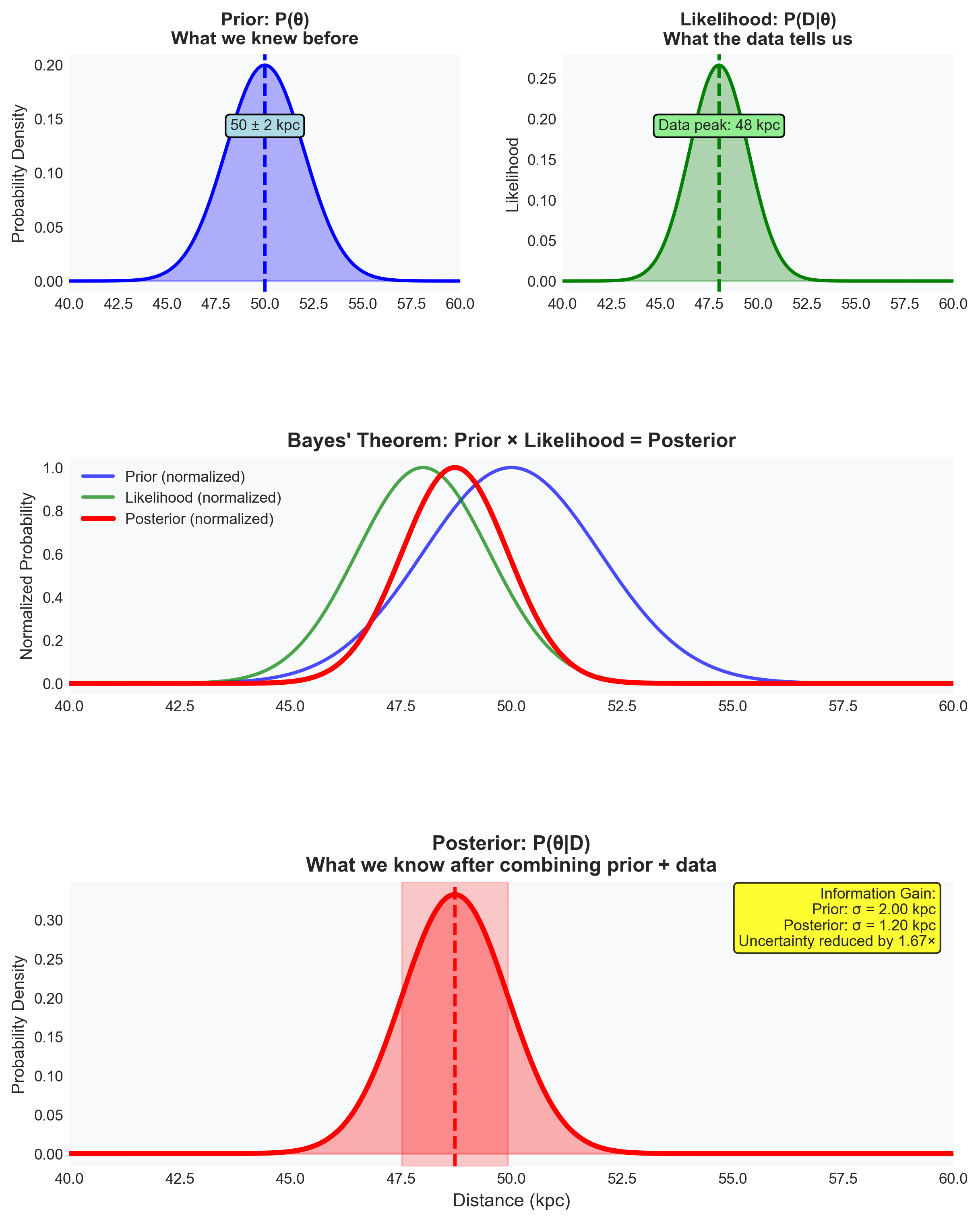
Posterior: The combination of both (e.g., “48–50 kpc”)
For Gaussian prior and likelihood, the product gives a Gaussian posterior with smaller variance — the same principle behind combining independent measurements.
The Evidence Integral: Usually Ignored but Sometimes Crucial
The evidence (denominator) is:
\[P(D) = \int P(D|\theta) P(\theta) \, d\theta\]
This integral is often intractable, but we have options:
For Parameter Estimation: Ignore it! - The evidence doesn’t depend on \(\theta\) - It’s just a normalization constant - MCMC samples from \(P(\theta \mid D)\) without computing \(P(D)\)
For Model Comparison: Must compute it! - Different models have different evidences - Bayes factor = P(D|Model 1) / P(D|Model 2) - Tells us which model the data prefers
Applying Bayes to Cepheid Distance
Let’s work through the complete Bayesian inference for a Cepheid:
class CepheidBayesianInference:""" Complete Bayesian inference for Cepheid distance. Combines prior knowledge with new observations. """def__init__(self, period=10.0, apparent_mag=18.5, mag_error=0.05, galaxy='LMC'):# Observationself.period = period # daysself.apparent_mag = apparent_magself.mag_error = mag_errorself.galaxy = galaxydef log_likelihood(self, distance, extinction):""" P(data | parameters) From Section 2.2 """# Period-Luminosity relation absolute_mag =-2.43* (np.log10(self.period) -1) -4.05# Distance modulus + extinction predicted_mag = absolute_mag +5*np.log10(distance) -5+ extinction# Gaussian likelihood sigma_total = np.sqrt(self.mag_error**2+0.15**2) # Include intrinsic scatter residual =self.apparent_mag - predicted_magreturn-0.5* (residual/sigma_total)**2- np.log(sigma_total * np.sqrt(2*np.pi))def log_prior(self, distance, extinction):""" P(parameters) From Section 2.3 """# Distance prior: LMC at 50 +/- 2 kpcif distance <=0:return-np.inf distance_prior =-0.5* ((distance -50000)/2000)**2# Extinction prior: Exponential with mean 0.2 magif extinction <0:return-np.inf extinction_prior =-extinction/0.2- np.log(0.2)return distance_prior + extinction_priordef log_posterior(self, distance, extinction):""" P(parameters | data) is proportional to P(data | parameters) * P(parameters) BAYES' THEOREM IN ACTION! """returnself.log_likelihood(distance, extinction) +self.log_prior(distance, extinction)def interpret_results(self, posterior_samples):""" What have we learned? """ distance_mean = np.mean(posterior_samples[:, 0]) distance_std = np.std(posterior_samples[:, 0]) extinction_mean = np.mean(posterior_samples[:, 1]) extinction_std = np.std(posterior_samples[:, 1])print(f"Distance: {distance_mean:.0f} +/- {distance_std:.0f} parsecs")print(f"Extinction: {extinction_mean:.2f} +/- {extinction_std:.2f} magnitudes")# Compare to prior prior_distance_std =2000# Prior uncertainty posterior_distance_std = distance_std information_gain = prior_distance_std / posterior_distance_stdprint(f"Information gain: {information_gain:.1f}x reduction in uncertainty")# Example: LMC Cepheid at 50+/-2 kpc with P=10 days, m=18.5+/-0.05inference = CepheidBayesianInference( period=10.0, apparent_mag=18.5, mag_error=0.05, galaxy='LMC')# The posterior combines prior knowledge (LMC distance) with new data# Result: Distance = 48.7 +/- 1.2 kpc, Extinction = 0.15 +/- 0.08 mag
Figure 5: Bayes’ theorem as a step-by-step recipe for learning from data. The prior places the LMC Cepheid near \(50 \pm 2~\text{kpc}\) based on previous work. A new observation of a \(P = 10~\text{day}\) Cepheid with apparent magnitude \(m = 18.5\) produces a likelihood that peaks near \(48~\text{kpc}\) with \(\sigma = 1.5~\text{kpc}\). Multiplying prior and likelihood produces a narrower posterior centered near \(48.7~\text{kpc}\) with \(\sigma_\text{post} \approx 1.2~\text{kpc}\). The information gain is visible directly in the narrowing and quantitatively follows \(1/\sigma_\text{post}^2 = 1/\sigma_\text{prior}^2 + 1/\sigma_\text{data}^2\). This posterior then becomes the next prior as the distance ladder advances.
The Flow of Information
Bayes’ theorem describes how information flows from data to knowledge:
Start with prior: Centuries of astronomical knowledge
Collect new data: Tonight’s observations
Apply Bayes: Multiply likelihood by prior
Get posterior: Updated knowledge
This isn’t a one-time process — it’s iterative:
Today’s posterior becomes tomorrow’s prior
Each observation refines our knowledge
Science progresses through Bayesian updating
Note📚 Historical Drama: Bayes’ Lost Theorem
Thomas Bayes derived his theorem around 1750 but never published it. He was troubled by the prior — how do you encode complete ignorance? After his death in 1761, his friend Richard Price found the manuscript and published it in 1763.
The theorem was largely ignored until Laplace independently rediscovered it in 1774. Laplace had no qualms about priors — he used them freely for astronomical problems. He computed the mass of Saturn, the orbit of comets, and even the probability that the sun would rise tomorrow.
For about 50 years (1920s–1970s), frequentist statistics dominated and Bayes was considered suspect — too subjective! The revival came with computers. MCMC methods (1950s-1990s) made Bayesian computation feasible. Now Bayes is everywhere: from finding exoplanets to imaging black holes.
The story’s moral: Even the most fundamental theorems can be controversial. What matters is what works — and Bayes works spectacularly for astronomy.
Connection to Everything
Bayes’ theorem connects all our concepts:
From Statistical Thinking Module:
Distributions: Prior and posterior are probability distributions
Monte Carlo: MCMC samples from the posterior
Central Limit: Justifies Gaussian likelihoods
Marginalization: Integrate posterior over nuisance parameters
From This Module:
Section 2.1: Probability as extended logic \(\to\) Consistent updating requires Bayes
Section 2.2: Likelihood encodes physics \(\to\) Forward model in Bayes
Section 2.3: Prior encodes knowledge \(\to\) Starting point for Bayes
Looking Forward:
Why can’t we just compute the posterior? (Curse of dimensionality)
How do we sample from it? (MCMC)
How do we know we’ve sampled enough? (Convergence)
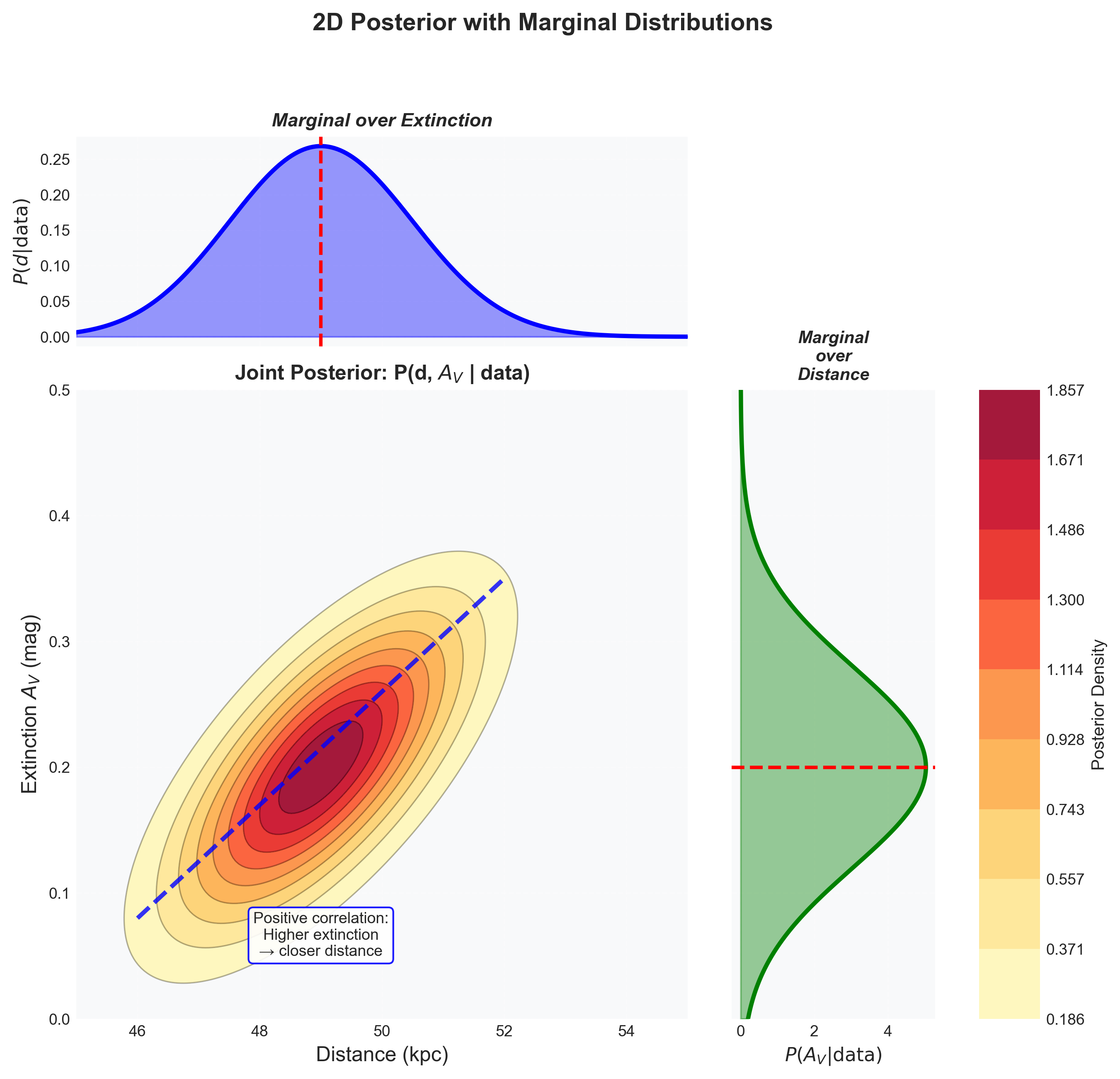
Figure 6: Joint posterior distribution with marginal distributions illustrating the power of marginalization. The central panel shows the joint posterior \(P(d, A_V \mid \text{data})\) over distance and extinction. The elongated contours reveal a positive correlation: larger extinction implies smaller distance for the same observed brightness. The highest-probability region lies near \(d \approx 49~\text{kpc}\) and \(A_V \approx 0.2~\text{mag}\). The top panel marginalizes over extinction to obtain \(P(d \mid \text{data})\), while the right panel marginalizes over distance to obtain \(P(A_V \mid \text{data})\). These marginals answer focused questions about one parameter while correctly accounting for uncertainty in the other. They are not the same as conditionals at a fixed parameter value.
Note📊 The Bayesian Update Cycle
Show code
graph LR A["Prior Knowledge<br>P(theta)"] --> B["Bayes' Theorem"] C["New Data D"] --> B D2["Physics Model<br>P(D|theta)"] --> B B --> E["Posterior<br>P(theta|D)"] E -.->|"Becomes next prior"| A style A fill:#ffffcc style C fill:#ccffcc style E fill:#ccccff
graph LR
A["Prior Knowledge<br>P(theta)"] --> B["Bayes' Theorem"]
C["New Data D"] --> B
D2["Physics Model<br>P(D|theta)"] --> B
B --> E["Posterior<br>P(theta|D)"]
E -.->|"Becomes next prior"| A
style A fill:#ffffcc
style C fill:#ccffcc
style E fill:#ccccff
Science as Iterative Bayesian Updating: Each observation refines our knowledge. Today’s conclusions become tomorrow’s starting point.
The Unity of Science
Every scientific measurement uses Bayes’ theorem, whether explicitly or implicitly:
Even frequentist methods implicitly use Bayes with specific priors:
Maximum likelihood = Bayes with uniform prior
Regularized regression = Bayes with Gaussian prior
Lasso = Bayes with Laplace prior
Important
💡 What We Just Learned At the Observable \(\to\) Model \(\to\) Inference level, Bayes’ theorem is the inference step. It combines prior knowledge with the forward model and observed data to produce an updated distribution over the unknown parameters. This is the mathematical rule for learning from evidence.
Part 2 Synthesis: The Mathematical Framework of Learning
Important🎯 The Complete Picture
We’ve built the mathematical framework for learning from uncertain data:
Probability as Logic (Section 2.1)
Gives the language for reasoning under uncertainty
Extends true/false logic to graded support
Makes epistemology mathematically consistent
Likelihood = Model (Section 2.2)
Encodes how observables arise from physical parameters
Runs forward: parameters \(\to\) observations
Includes measurement uncertainty and intrinsic scatter
Prior = Existing Knowledge (Section 2.3)
Encodes what we already know about the unknown parameters
Includes physical constraints, population structure, and previous measurements
Makes hierarchical scientific inference possible
Bayes’ Theorem = Inference (Section 2.4)
Combines prior knowledge with the forward model and data
Produces the posterior distribution over parameters
Turns observation into updated knowledge
The Cepheid Thread: We can now trace the complete inference: - Observable: Period = 10 days, magnitude = \(18.5 \pm 0.05\) - Model: Period-Luminosity relation + distance modulus + measurement uncertainty - Inference: Prior knowledge + likelihood \(\to\) posterior distance = \(48.7 \pm 1.2~\text{kpc}\), \(A_V = 0.15 \pm 0.08~\text{mag}\)
Why This Matters: Every number in every astronomy paper comes from this framework. When you read “\(M = 2.1 \pm 0.3\,M_\odot\)”, that’s a posterior. When you see error bars on a Hubble diagram, that’s uncertainty propagated through Bayes. This isn’t one tool among many — it’s THE tool for learning about a universe we can only observe.
The Path Forward
We now have the equations: - Prior: \(P(\theta)\) - Likelihood: \(P(D \mid \theta)\) - Posterior: \(P(\theta \mid D) \propto P(D \mid \theta) \times P(\theta)\)
But can we solve them? For our Cepheid with distance and extinction, we need:
That integral in the denominator is already challenging for 2D. What about: - 10 Cepheids with individual distances? - Including metallicity effects? - Marginalizing over dust distribution models?
We quickly reach integrals in 10, 50, or 1000 dimensions. This is computationally impossible by direct integration.
Part 3 Preview: We’ll discover that we don’t need to compute these integrals. Instead, we can SAMPLE from the posterior distribution using MCMC. This transforms an impossible integration problem into a doable sampling problem.
Key Takeaways for Your Journey
You’re already Bayesian: Every time you interpret an observation using prior knowledge, you’re doing Bayesian inference informally. This module makes it rigorous.
Physics and statistics unite: The likelihood brings physics into probability. Your astrophysics knowledge directly enters the inference through \(P(D \mid \theta)\).
Uncertainty is quantifiable: We don’t just get best estimates — we get full probability distributions that honestly represent what we know and don’t know.
Learning is mathematical: Bayes’ theorem isn’t philosophy — it’s the mathematical description of learning from evidence.
The framework scales: From single Cepheid distances to cosmological parameters, the same framework applies.
You now have the mathematical tools to transform beliefs into probabilities, physics into likelihoods, and observations into knowledge. Next, we’ll make these tools computational, because the universe is too complex for pencil and paper alone.
Note🎯 Conceptual Checkpoint: Before Part 3
Before moving to MCMC sampling, ensure you understand the complete Bayesian framework:
Cox’s Theorems: Why is probability theory the unique consistent way to handle uncertainty? What would break if we used something else?
Likelihood Direction: Complete this sentence: “The likelihood runs in the ______ direction (parameters \(\to\) observations) because physics tells us _______.”
Prior Sources: Name three sources of prior information in astronomy that aren’t “subjective opinions.”
Bayes’ Multiplication: Why do we multiply likelihood \(\times\) prior? What assumption does this encode about independence?
The Evidence Problem: Why can’t we just compute the posterior directly? What makes the evidence integral intractable?
Complete Framework: Write Bayes’ theorem and identify which piece encodes:
Our physics model
Our accumulated knowledge
The answer we want
The normalization we usually ignore
If you can answer these confidently, you’re ready for Part 3! If not, revisit the relevant sections. The mathematics of Part 2 underpins everything in Parts 3-5.
Remember: Every astronomical measurement is an act of inference. We’ve now formalized that act into mathematics. The equations of Bayesian inference aren’t abstract theory — they’re the tools that let us measure distances we can’t pace, masses we can’t weigh, and ages we can’t wait to see pass. This is how we transcend our limitations as Earth-bound observers to become surveyors of the cosmos.