Part 2: Quadrature - From Photon Counts to Dark Matter Halos
Module 2: Static Problems & Quadrature | COMP 536
Learning Objectives
By the end of this section, you will be able to:
The Fundamental Challenge
While differentiation is a local operation (needing only nearby points), integration is global — we must consider the entire domain. Quadrature (numerical integration) transforms the continuous integral:
\[I = \int_a^b f(x) dx\]
into a discrete sum:
\[I \approx \sum_{i=0}^n w_i f(x_i)\]
The art lies in choosing:
- The points \(x_i\) (where to sample)
- The weights \(w_i\) (how much each sample contributes)
- The number \(n\) (balancing accuracy vs computation)
Physical Motivation: Why Astronomers Integrate
Integration is everywhere in astronomy because we observe integrated quantities:
Spectroscopy: We don’t see individual photons but integrated flux \[F = \int_{\lambda_1}^{\lambda_2} F_\lambda d\lambda\]
Photometry: CCD pixels integrate photons over exposure time \[N_\text{photons} = \int_0^T \Phi(t) dt\]
Structure: Mass distributions require volume integrals \[M(<r) = \int_0^r 4\pi r'^2 \rho(r') dr'\]
Cosmology: Distances involve integrating through expanding space \[d_L = (1+z) \int_0^z \frac{c\,dz'}{H(z')}\]
Each context demands different accuracy, and the function properties (smooth vs oscillatory, bounded vs singular) determine the best method.
Condition number: For integration, oscillatory or rapidly varying functions are ill-conditioned — small changes in sampling can cause large errors.
Building Integration Methods: From Rectangles to Optimality
The Riemann Sum Foundation
The definition of the Riemann integral suggests the simplest approximation:
\[\int_a^b f(x)dx = \lim_{n \to \infty} \sum_{i=0}^{n-1} f(x_i^*) \Delta x_i\]
where \(x_i^* \in [x_i, x_{i+1}]\) and \(\Delta x_i = x_{i+1} - x_i\).
Different choices of \(x_i^*\) give different methods:
- Left endpoint: Rectangle rule (left)
- Right endpoint: Rectangle rule (right)
- Midpoint: Midpoint rule
- Average of endpoints: Trapezoidal rule
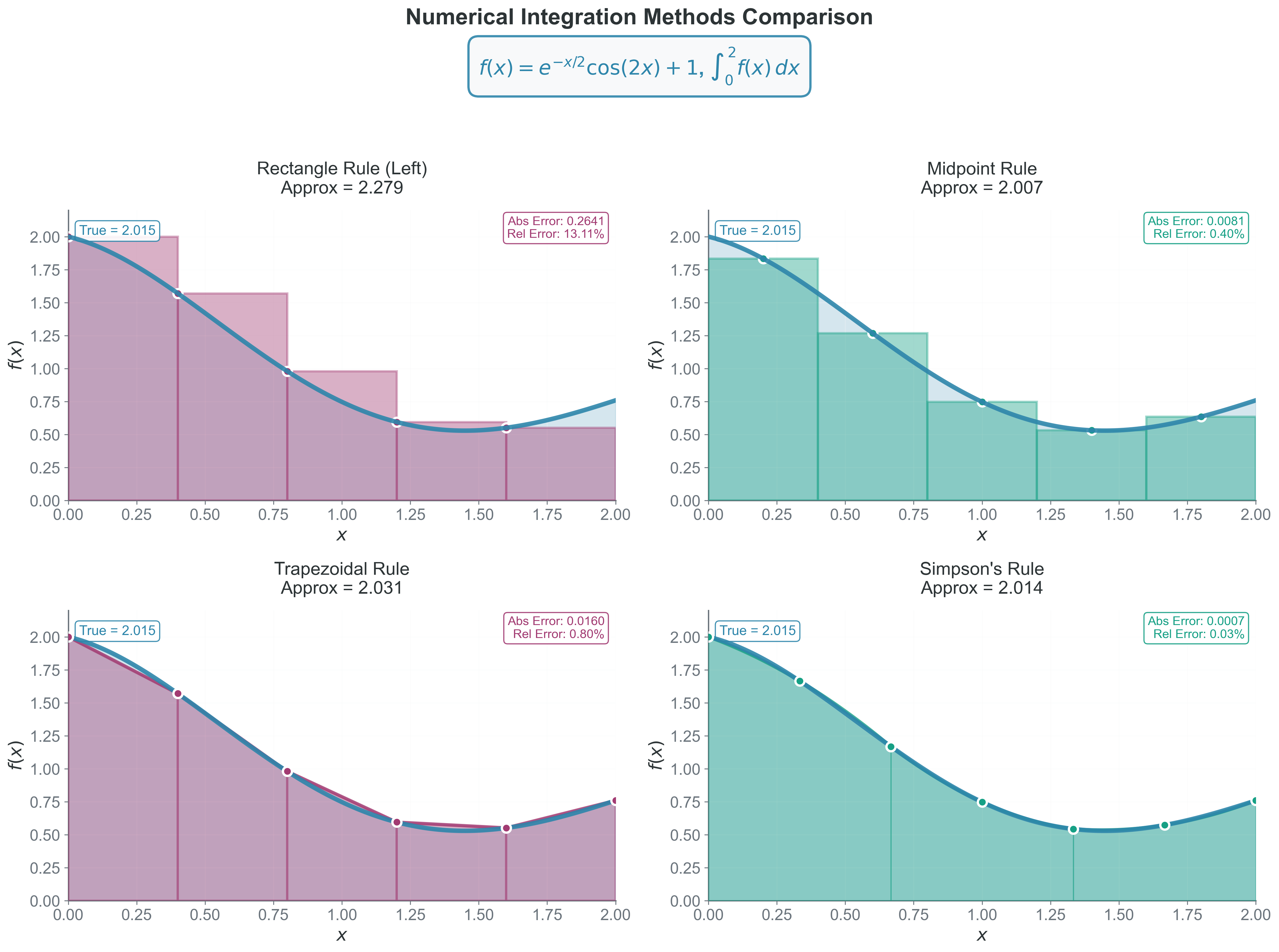
Method 1: Rectangle Rule - The Starting Point
Why we care: The simplest possible approximation — helps understand error analysis that applies to all methods.
Mathematical Formulation
For uniform spacing \(h = (b-a)/n\):
\[I \approx h \sum_{i=0}^{n-1} f(a + ih) \quad \text{(left rectangle)}\]
Error Analysis via Taylor Series
On each subinterval \([x_i, x_{i+1}]\):
\[\int_{x_i}^{x_{i+1}} f(x)dx = \int_{x_i}^{x_{i+1}} \left[f(x_i) + f'(x_i)(x-x_i) + \frac{f''(\xi)}{2}(x-x_i)^2\right]dx\]
Evaluating: \[= f(x_i)h + f'(x_i)\frac{h^2}{2} + O(h^3)\]
The rectangle rule uses only \(f(x_i)h\), so the local error is:
\[E_{local} = \frac{h^2}{2}f'(\xi)\]
Over \(n\) intervals:
\[E_{total} = n \cdot O(h^2) = \frac{b-a}{h} \cdot O(h^2) = O(h)\]
First-order method: Global error proportional to step size.
This is a first-order method—halving \(h\) halves the error.
Implementation
def rectangle_rule(f, a, b, n):
"""Left rectangle rule"""
h = (b - a) / n
total = 0
for i in range(n):
x = a + i * h
total += f(x)
return h * totalWhy Not to Use Rectangle Rule
- Only first-order accurate
- Systematically over/underestimates for monotonic functions
- Poor for oscillatory functions
- Mainly pedagogical value
Method 2: Trapezoidal Rule - The Workhorse
Why we care: The workhorse of experimental data integration — robust and simple.
Geometric Intuition
Instead of rectangles, connect consecutive points with straight lines, creating trapezoids. The area of each trapezoid averages the function values at its endpoints.
Mathematical Formulation
The area of a trapezoid with parallel sides \(f(x_i)\) and \(f(x_{i+1})\) and height \(h\) is:
\[A_i = \frac{h}{2}[f(x_i) + f(x_{i+1})]\]
Summing over all intervals:
\[I \approx \sum_{i=0}^{n-1} \frac{h}{2}[f(x_i) + f(x_{i+1})] = h\left[\frac{f(a)}{2} + \sum_{i=1}^{n-1} f(x_i) + \frac{f(b)}{2}\right]\]
Error Analysis
Using Taylor expansion around the midpoint \(x_i + h/2\):
\[f(x_i) = f(x_i + h/2) - \frac{h}{2}f'(x_i + h/2) + \frac{h^2}{8}f''(x_i + h/2) + O(h^3)\]
\[f(x_{i+1}) = f(x_i + h/2) + \frac{h}{2}f'(x_i + h/2) + \frac{h^2}{8}f''(x_i + h/2) + O(h^3)\]
The trapezoidal approximation on \([x_i, x_{i+1}]\):
\[\frac{h}{2}[f(x_i) + f(x_{i+1})] = hf(x_i + h/2) + \frac{h^3}{12}f''(x_i + h/2) + O(h^4)\]
Since the exact integral is \(hf(x_i + h/2) + O(h^3)\):
Local error: \(E_{local} = -\frac{h^3}{12}f''(\xi)\)
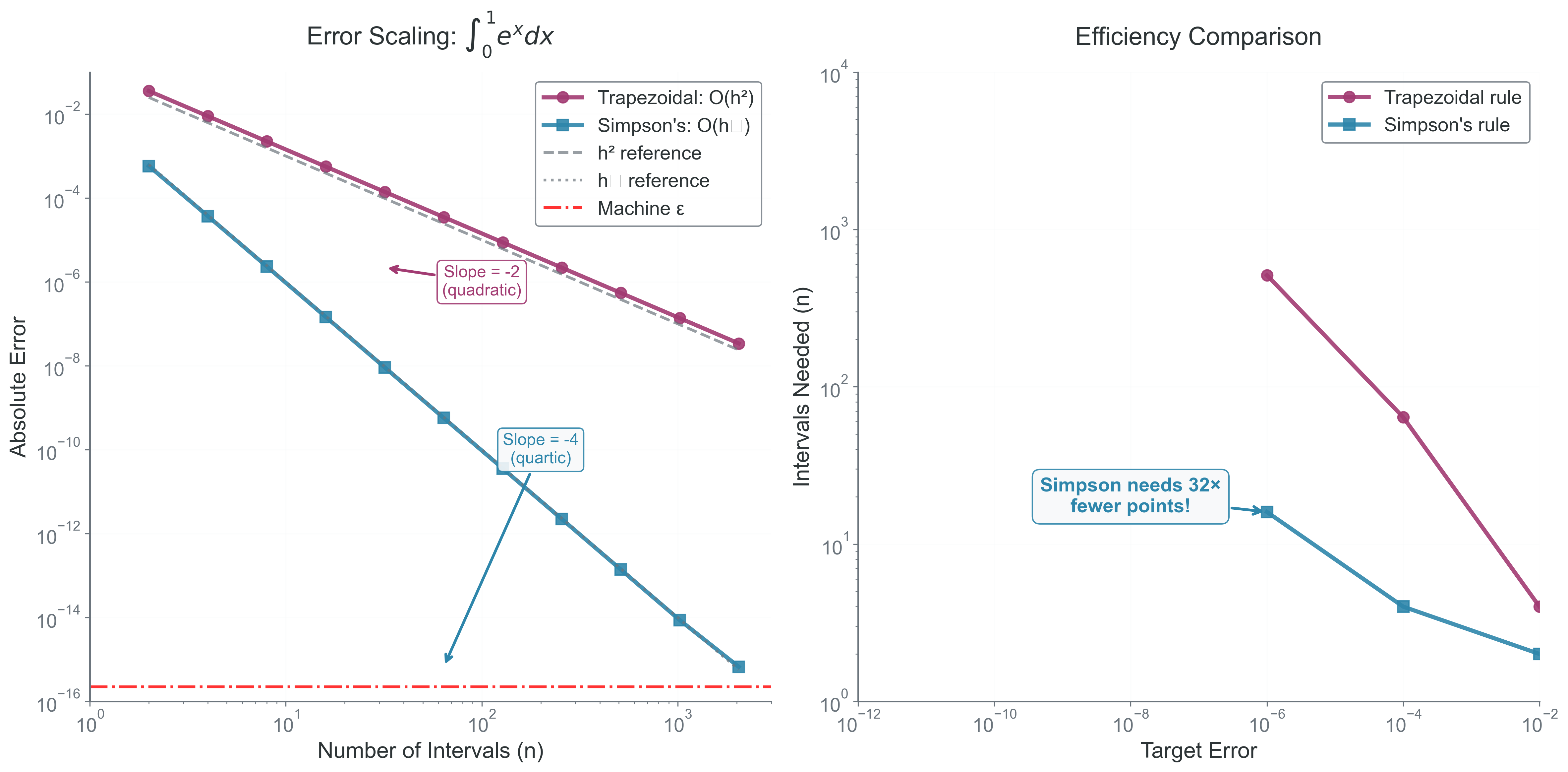
Second-order method: Global error proportional to step size squared. Doubling points gives 4\(\times\) accuracy.
Global error: \(\boxed{E_{total} = -\frac{(b-a)h^2}{12}f''(\xi)}\) for some \(\xi \in [a,b]\)
This is a second-order method!
Common Failure Modes and Fixes
| Problem | Symptom | Solution |
|---|---|---|
| Singularities | Infinite result | Subtract singularity analytically |
| Oscillations | Poor convergence | Increase n or use adaptive spacing |
| Noisy data | Erratic results | Smooth first or use fewer points |
| Discontinuities | Wrong answer | Split integral at discontinuity |
Method 3: Simpson’s Rule - Parabolic Perfection
Why we care: When your function is smooth and you want high accuracy with moderate computational cost.
The Key Insight
Instead of linear interpolation (trapezoids), use quadratic interpolation (parabolas) through consecutive triplets of points.
Derivation via Interpolation
For three equally-spaced points \(x_0, x_1, x_2\) with \(x_1 = x_0 + h\) and \(x_2 = x_0 + 2h\), the unique parabola through \((x_i, f(x_i))\) is:
\[p(x) = f(x_0)\frac{(x-x_1)(x-x_2)}{2h^2} - f(x_1)\frac{(x-x_0)(x-x_2)}{h^2} + f(x_2)\frac{(x-x_0)(x-x_1)}{2h^2}\]
Integrating this parabola from \(x_0\) to \(x_2\):
\[\int_{x_0}^{x_2} p(x)dx = \frac{h}{3}[f(x_0) + 4f(x_1) + f(x_2)]\]
These are the famous Simpson weights: 1, 4, 1.
Composite Simpson’s Rule
For \(n\) intervals (must be even):
\[\boxed{I \approx \frac{h}{3}\left[f(a) + 4\sum_{i=1,3,5...}^{n-1} f(x_i) + 2\sum_{i=2,4,6...}^{n-2} f(x_i) + f(b)\right]}\]
The pattern of weights is: - First point: 1 - Odd indices (1,3,5,…,n-1): 4 - Even indices (2,4,6,…,n-2): 2
- Last point: 1
Error Analysis and the Fourth-Order Miracle
Through careful Taylor series analysis, the local error for Simpson’s rule on interval \([x_i, x_{i+2}]\) is:
\[E_{local} = -\frac{h^5}{90}f^{(4)}(\xi)\]
Fourth-order method: Error decreases as \(h^4\)—remarkably accurate for smooth functions!
Global error: \(\boxed{E_{total} = -\frac{(b-a)h^4}{180}f^{(4)}(\xi)}\)
Simpson’s rule is fourth-order accurate despite using only parabolas!
Why Simpson’s Rule is Fourth-Order
The “miracle” of Simpson’s fourth-order accuracy comes from symmetry. When we integrate the interpolating parabola, the \(f'''(\xi)\) term (which would give \(O(h^3)\) error) has odd symmetry about the midpoint and integrates to zero:
\[\int_{x_0}^{x_2} (x-x_1)^3 dx = 0\]
This cancellation is automatic — we get fourth-order accuracy “for free” by using symmetric intervals! Since the error term involves \(f^{(4)}\), and the fourth derivative of any cubic polynomial is zero, Simpson’s rule integrates cubic polynomials exactly.
When Simpson’s Rule Shines
- Smooth functions with continuous fourth derivative
- Periodic functions
- When high accuracy is needed with moderate \(n\)
- Functions from physical models (usually smooth)
Common Failure Modes and Fixes
| Problem | Symptom | Solution |
|---|---|---|
| Odd n | Won’t work | Add one interval or use trapezoid for last |
| Noisy data | Amplifies noise | Use trapezoidal instead |
| Discontinuous \(f^{(4)}\) | Poor convergence | Split at discontinuity |
| Sharp peaks | Misses features | Use adaptive refinement |
- Why must n be even for Simpson’s rule?
- What happens if f(x) is exactly a cubic polynomial?
- How does the error scale if we double n?
- When would Simpson’s rule perform poorly?
Method 4: Gaussian Quadrature - Optimal Point Placement
Why we care: Sometimes being clever about WHERE you sample beats taking MORE samples.
The Revolutionary Idea
All previous methods used equally-spaced points. But what if we could choose both the points AND weights optimally?
Gauss’s insight: For \(n\) points, we can make the method exact for all polynomials up to degree \(2n-1\) by choosing specific locations. These points are the roots of Legendre polynomials, which have special orthogonality properties that maximize accuracy.
Example: 2-Point Gaussian Quadrature
Instead of evaluating at equally-spaced points, Gaussian quadrature uses special points. For 2 points on \([-1,1]\): - Points: \(x_1 = -\frac{1}{\sqrt{3}} \approx -0.577\), \(x_2 = \frac{1}{\sqrt{3}} \approx 0.577\) - Weights: \(w_1 = w_2 = 1\)
This seemingly arbitrary choice makes the method exact for all cubic polynomials!
In Practice
You won’t derive Gauss points yourself. Instead:
from scipy.special import roots_legendre
# Get n Gauss points and weights for [-1,1]
points, weights = roots_legendre(n)
# Transform to general interval [a,b]
x_gauss = (b-a)/2 * points + (a+b)/2
w_gauss = (b-a)/2 * weights
# Compute integral
integral = sum(w * f(x) for x, w in zip(x_gauss, w_gauss))When Gaussian Quadrature Matters
- When you control where to sample (not experimental data)
- For very smooth functions
- When function evaluations are expensive (fewer points needed)
- As the foundation for spectral methods in advanced simulations
Key Takeaway: This principle — optimal placement beats more samples — appears throughout computational physics, from choosing timesteps in orbit integration to placing grid points in PDE solvers.
Method 5: Monte Carlo Integration - When Dimensions Explode
Why we care: The only practical method for high-dimensional integrals that appear in statistical mechanics, quantum mechanics, and Bayesian inference.
Understanding Dimensions in Integration
Integration dimension: The number of independent variables being integrated over. A triple integral \(\int\int\int\) f(x,y,z) dxdydz is 3-dimensional, not because it’s in 3D space, but because we integrate over 3 variables.
When we talk about “dimensions” in Monte Carlo integration, we mean the number of integration variables, not spatial dimensions:
- 1D integral: \(\int_a^b f(x) dx\) (one integration variable)
- 2D integral: \(\int \int_R f(x,y) dxdy\) (two integration variables)
- 6N-D integral: Phase space integral over N particles with 3 position and 3 momentum components each
For example, computing the partition function for 100 atoms requires a 300-dimensional integral (3 position coordinates per atom)!
The Curse of Dimensionality
Curse of dimensionality: Exponential growth of computational cost with dimension for grid-based methods.
For a \(d\)-dimensional integral with \(n\) points per dimension, deterministic methods need \(n^d\) evaluations:
- 1D: 100 points
- 2D: \(100^{2}\) = 10,000 points
- 3D: \(100^{3}\) = 1,000,000 points
- 10D: \(100^{10}\) = \(10^{20}\) points (impossible!)
This exponential growth makes grid-based methods impossible for \(d > 5\).
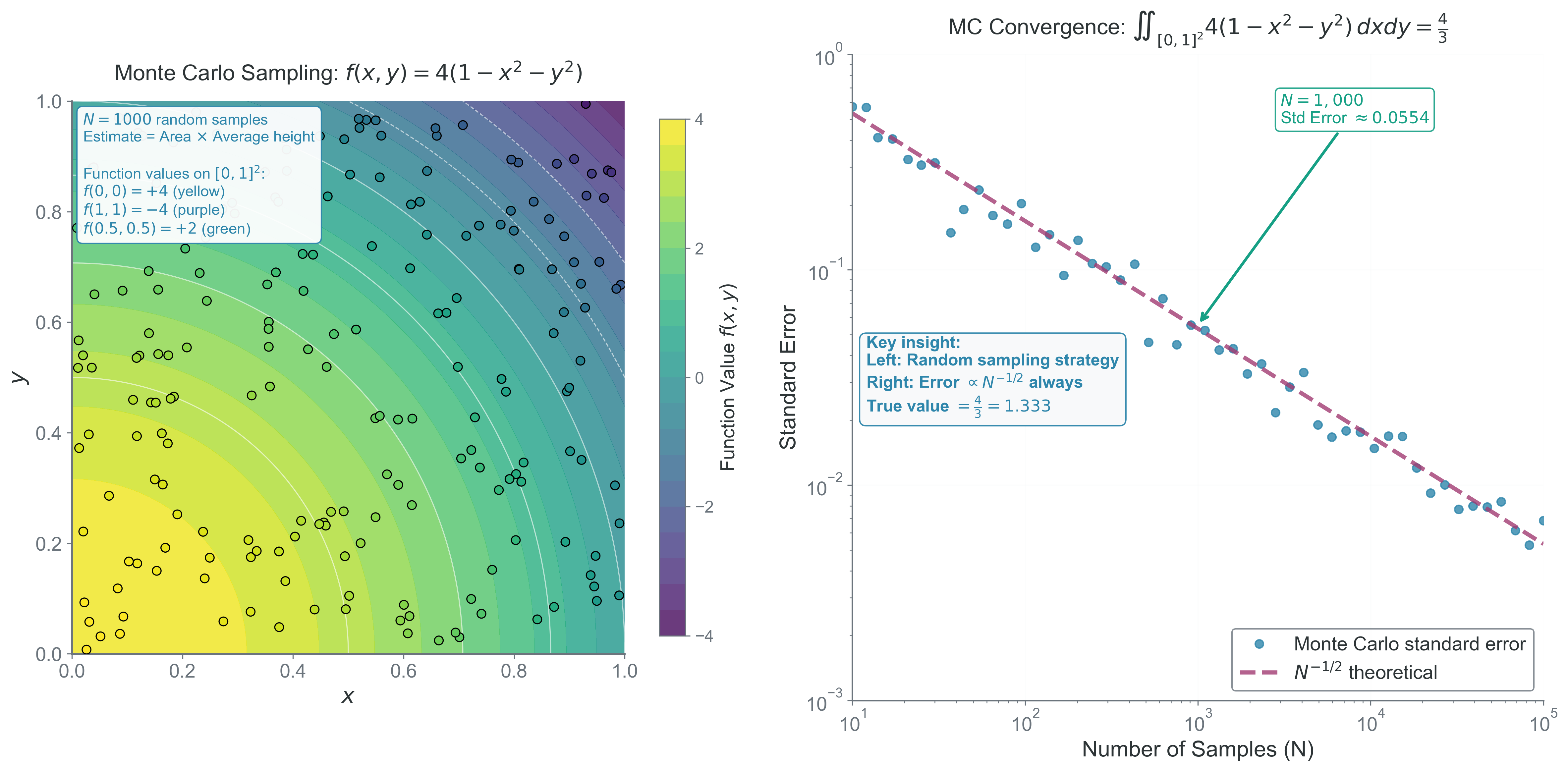
The Monte Carlo Solution
Randomly sample \(N\) points \(\vec{x}_i\) in the domain \(\Omega\):
\[I = \int_\Omega f(\vec{x})d\vec{x} \approx \hat{I} = \frac{V(\Omega)}{N}\sum_{i=1}^N f(\vec{x}_i)\]
where \(V(\Omega)\) is the volume of the domain.
Error Analysis
Central Limit Theorem: The sum of many independent random variables tends toward a normal distribution, regardless of the original distribution.
For the Monte Carlo estimator \(\hat{I} = \frac{V(\Omega)}{N}\sum_{i=1}^N f(\vec{x}_i)\):
Step 1: The expected value of our estimator is the true integral: \[\mathbb{E}[\hat{I}] = \frac{V(\Omega)}{N} \sum_{i=1}^N \mathbb{E}[f(\vec{x}_i)] = V(\Omega) \cdot \mathbb{E}[f] = I\]
Step 2: The variance of the estimator is: \[\text{Var}[\hat{I}] = \text{Var}\left[\frac{V(\Omega)}{N}\sum_{i=1}^N f(\vec{x}_i)\right] = \frac{V(\Omega)^2}{N^2} \cdot N \cdot \text{Var}[f] = \frac{V(\Omega)^2 \sigma_f^2}{N}\]
where \(\sigma_f^2 = \text{Var}[f] = \mathbb{E}[f^2] - \mathbb{E}[f]^2\) is the variance of \(f\) over the domain.
Step 3: The standard error (standard deviation of the estimator) is: \[\boxed{\sigma_I = \sqrt{\text{Var}[\hat{I}]} = \frac{V(\Omega)\sigma_f}{\sqrt{N}}}\]
Dimension-independent convergence: Monte Carlo error scales as \(N^{-1/2}\) regardless of dimension d!
Key insight: Error \(\propto N^{-1/2}\) independent of dimension \(d\)!
This assumes: - Independent random samples - Finite variance of the integrand (\(\sigma_f < \infty\)) - Sufficient samples for CLT to apply (typically N > 30)
When Monte Carlo Wins
| Dimension | Grid Points for 1% Error | Monte Carlo Points for 1% Error |
|---|---|---|
| 1 | 100 | 10,000 |
| 2 | 10,000 | 10,000 |
| 3 | 1,000,000 | 10,000 |
| 5 | \(10^{10}\) | 10,000 |
| 10 | \(10^{20}\) | 10,000 |
Above ~4 dimensions, Monte Carlo becomes superior!
Common Failure Modes and Fixes
| Problem | Symptom | Solution |
|---|---|---|
| Infinite variance | No convergence | Use importance sampling |
| Rare events | Poor sampling | Use stratified sampling |
| Correlation | Slower convergence | Use quasi-random sequences |
| Small N | Large uncertainty | Can’t fix — need more samples |
Monte Carlo Radiative Transfer uses this principle: - Photon paths are high-dimensional integrals over all possible scattering sequences - Each photon is a Monte Carlo sample - Error decreases as \(1/\sqrt{N_{photons}}\) - Handles complex 3D geometries naturally without grids
Adaptive Methods and Richardson Extrapolation
Adaptive Quadrature
When functions vary rapidly in some regions but are smooth elsewhere:
def adaptive_simpson(f, a, b, tol):
"""Recursively refine where needed"""
# Compute with n and 2n points
I1 = simpson(f, a, b, n=10)
I2 = simpson(f, a, b, n=20)
if abs(I2 - I1) < tol:
return I2
else:
mid = (a + b) / 2
left = adaptive_simpson(f, a, mid, tol/2)
right = adaptive_simpson(f, mid, b, tol/2)
return left + rightRichardson Extrapolation
Richardson Extrapolation: Using results at different resolutions to cancel leading error terms and achieve higher accuracy.
If your method has error \(I(h) = I_{exact} + Ch^p + O(h^{p+1})\), compute at two resolutions:
\[I_{better} = \frac{2^p I(h/2) - I(h)}{2^p - 1}\]
This cancels the leading error term! For trapezoidal rule (p=2):
\[I_{better} = \frac{4 I(h/2) - I(h)}{3}\]
This gives fourth-order accuracy from a second-order method!
Real Application: Galaxy Luminosity from Spectrum
Astronomers measure galaxy spectra as discrete samples at wavelengths \(\lambda_i\) with fluxes \(F_i\). The total luminosity requires integration:
\[L = 4\pi d^2 \int_{\lambda_{min}}^{\lambda_{max}} F_\lambda d\lambda\]
Challenges
- Irregular wavelength spacing from different instruments
- Noise in flux measurements
- Missing data from atmospheric absorption
- Emission lines need high resolution
Solution Strategy
For irregular spacing, use trapezoidal rule with variable h:
def integrate_spectrum(wavelengths, fluxes):
"""Integrate spectrum with irregular spacing"""
total = 0
for i in range(len(wavelengths) - 1):
dλ = wavelengths[i+1] - wavelengths[i]
f_avg = (fluxes[i+1] + fluxes[i]) / 2
total += dλ * f_avg
return totalFor emission lines: ensure ~10 points across line width or fit Gaussian profile and integrate analytically.
Choosing the Right Integration Method
Method Comparison Summary
| Method | Order | Pros | Cons | Best For |
|---|---|---|---|---|
| Rectangle | \(O(h)\) | Simple | Inaccurate | Teaching only |
| Trapezoid | \(O(h^2)\) | Robust, handles irregular spacing | Moderate accuracy | Experimental data, noisy functions |
| Simpson | \(O(h^4)\) | Very accurate for smooth functions | Needs even n, amplifies noise | Smooth theoretical functions |
| Gaussian | \(O(h^{2n})\) | Optimal for polynomials | Need special points | When you control sampling |
| Monte Carlo | \(O(N^{-1/2})\) | Dimension-independent | Slow convergence | High dimensions (d > 4) |
Practical Guidelines
- Start simple: Try trapezoidal first — it often suffices
- Check smoothness: Plot your function before choosing
- Test convergence: Double n and see if result changes
- Consider cost: Is f(x) expensive to evaluate?
- Remember libraries: Use
scipy.integrate.quadfor production
Debugging Integration
Common integration bugs and their diagnosis:
| Symptom | Likely Cause | Fix |
|---|---|---|
| Error doesn’t decrease with n | Wrong implementation | Check weights and indices |
| Error plateaus at \(\sim 10^{-14}\) | Round-off dominance | Use fewer points or extended precision |
| Oscillating convergence | Under-resolving features | Increase n or use adaptive |
| Simpson gives weird results | Odd n | Ensure even intervals |
| Negative result for positive f | Overflow in sum | Use compensated summation |
| Monte Carlo not converging | Infinite variance | Check if \(\sigma_f\) is finite |
Bridge to Part 3: The Unity of Numerical Methods
You’ve now mastered two fundamental classes of problems: finding where functions equal zero and measuring areas under curves. These aren’t isolated techniques — they’re connected by deep mathematical principles.
In Part 3, we’ll explore these connections. You’ll see how root finding and integration are inverse operations, how the same error analysis principles govern both, and how to combine methods for complex problems. Most importantly, you’ll develop the intuition to choose the right method for any computational challenge.
The synthesis ahead will prepare you for the dynamic problems of Module 3, where these static methods become building blocks for simulating evolution through time.
Next: Part 3 - Synthesis